Utilizzo di TextBlob nell'industria
Proprio come sembra, TextBlob è un pacchetto Python per eseguire operazioni di analisi del testo semplici e complesse su dati testuali come codifica vocale, estrazione di frasi nominali, analisi del sentimento, classificazione, traduzione e altro. Sebbene ci siano molti più casi d'uso per TextBlob che potremmo trattare in altri blog, questo copre l'analisi dei Tweet per i loro sentimenti.
I sentimenti di analisi hanno un grande utilizzo pratico per molti scenari:
- Durante le elezioni politiche in una regione geografica, i tweet e altre attività sui social media possono essere monitorati per produrre exit poll stimati e risultati sul prossimo governo
- Varie aziende possono utilizzare l'analisi testuale sui social media per identificare rapidamente eventuali pensieri negativi che circolano sui social media in una determinata regione per identificare i problemi e risolverli
- Alcuni prodotti usano persino i tweet per stimare le tendenze mediche delle persone dalla loro attività sociale, come il tipo di tweet che stanno facendo, forse si stanno comportando suicidari, ecc.
Iniziare con TextBlob
Sappiamo che sei venuto qui per vedere del codice pratico relativo a un analizzatore sentimentale con TextBlob. Ecco perché manterremo questa sezione estremamente breve per introdurre TextBlob per i nuovi lettori. Solo una nota prima di iniziare è che usiamo a ambiente virtuale per questa lezione che abbiamo fatto con il seguente comando
python -m virtualenv textblobsorgente textblob/bin/activate/
Una volta che l'ambiente virtuale è attivo, possiamo installare la libreria TextBlob all'interno dell'ambiente virtuale in modo che gli esempi che creeremo in seguito possano essere eseguiti:
pip install -U textblobUna volta eseguito il comando sopra, non è così. TextBlob ha anche bisogno di accedere ad alcuni dati di training che possono essere scaricati con il seguente comando:
python -m textblob.download_corporaVedrai qualcosa di simile scaricando i dati richiesti:
Puoi usare anche Anaconda per eseguire questi esempi, il che è più semplice. Se vuoi installarlo sul tuo computer, guarda la lezione che descrive “Come installare Anaconda Python su Ubuntu 18.04 LTS” e condividi il tuo feedback.
Per mostrare un esempio molto rapido per TextBlob, ecco un esempio direttamente dalla sua documentazione:
da textblob import TextBlobtesto = "'
La minaccia del titolo di The Blob mi ha sempre colpito come il film definitivo
mostro: una massa insaziabilmente affamata, simile a un'ameba, in grado di penetrare
praticamente qualsiasi protezione, capace di... come un dottore condannato in modo agghiacciante
lo descrive--"assimilazione della carne al contatto.
Al diavolo i paragoni con la gelatina, è un concetto con più
devastante di potenziali conseguenze, non diversamente dallo scenario gray goo
proposto da teorici tecnologici timorosi di
l'intelligenza artificiale dilaga.
"'
blob = TextBlob (testo)
stampa (blob.tag)
stampa (blob.frasi nominative)
per frase in blob.frasi:
stampa (frase.sentimento.polarità)
blob.translate(to="es")
Quando eseguiamo il programma sopra, otterremo le seguenti parole tag e infine le emozioni che le due frasi nel testo di esempio dimostrano:
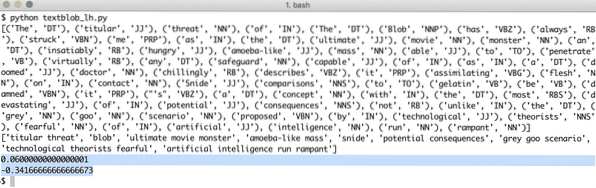
Tag parole ed emozioni ci aiuta a identificare le parole principali che effettivamente incidono sul calcolo del sentimento e sulla polarità della frase fornita al. Questo perché il significato e il sentimento delle parole cambiano nell'ordine in cui vengono usate, quindi tutto questo deve essere mantenuto dinamico.
Analisi del sentiment basata sul lessico
Qualsiasi Sentimento può essere semplicemente definito in funzione dell'orientamento semantico e dell'intensità delle parole usate in una frase. Con un approccio basato sul lessico per identificare le emozioni in determinate parole o frasi, ogni parola è associata a un punteggio che descrive l'emozione che la parola esibisce (o almeno cerca di esibire). Di solito, la maggior parte delle parole ha un dizionario predefinito sul loro punteggio lessicale, ma quando si tratta di umano, c'è sempre del sarcasmo, quindi quei dizionari non sono qualcosa su cui possiamo fare affidamento al 100%. Il dizionario WordStat Sentiment include più di 9164 modelli di parole negativi e 4847 positivi.
Infine, c'è un altro metodo per eseguire l'analisi del sentiment (fuori ambito per questa lezione) che è una tecnica di Machine Learning ma non possiamo utilizzare tutte le parole in un algoritmo ML poiché sicuramente dovremo affrontare problemi con l'overfitting. Possiamo applicare uno degli algoritmi di selezione delle caratteristiche come Chi Square o Mutual Information prima di addestrare l'algoritmo. Limiteremo la discussione dell'approccio ML solo a questo testo.
Utilizzo dell'API di Twitter
Per iniziare a ricevere tweet direttamente da Twitter, visita la home page dello sviluppatore dell'app qui:
https://sviluppatore.twitter.com/en/apps
Registra la tua domanda compilando il modulo così fornito:
Una volta che hai tutti i token disponibili nella scheda "Chiavi e token":
Possiamo utilizzare le chiavi per ottenere i tweet richiesti dall'API di Twitter, ma dobbiamo installare solo un altro pacchetto Python che fa il lavoro pesante per noi nell'ottenere i dati di Twitter:
pip install tweepyIl pacchetto di cui sopra verrà utilizzato per completare tutte le comunicazioni pesanti con l'API di Twitter. Il vantaggio per Tweepy è che non dobbiamo scrivere molto codice quando vogliamo autenticare la nostra applicazione per interagire con i dati di Twitter ed è automaticamente racchiusa in un'API molto semplice esposta tramite il pacchetto Tweepy. Possiamo importare il pacchetto sopra nel nostro programma come:
importa tweepyDopodiché, dobbiamo solo definire le variabili appropriate in cui possiamo tenere le chiavi Twitter che abbiamo ricevuto dalla console degli sviluppatori:
consumer_key = '[consumer_key]'consumer_key_secret = '[consumer_key_secret]'
access_token = '[access_token]'
access_token_secret = '[access_token_secret]'
Ora che abbiamo definito i segreti per Twitter nel codice, siamo finalmente pronti a stabilire una connessione con Twitter per ricevere i Tweet e giudicarli, insomma, analizzarli. Naturalmente, la connessione a Twitter deve essere stabilita utilizzando lo standard OAuth e Il pacchetto Tweepy tornerà utile per stabilire la connessione anche:
twitter_auth = tweepy.OAuthHandler(consumer_key, consumer_key_secret)Infine abbiamo bisogno della connessione:
api = tweepy.API(twitter_auth)Utilizzando l'istanza API, possiamo cercare su Twitter qualsiasi argomento che gli passiamo. Può essere una singola parola o più parole. Anche se raccomanderemo di usare il minor numero possibile di parole per la precisione. Proviamo un esempio qui:
pm_tweets = api.cerca("India")La ricerca sopra ci fornisce molti Tweet ma limiteremo il numero di tweet che riceviamo in modo che la chiamata non richieda troppo tempo, poiché deve essere successivamente elaborata anche dal pacchetto TextBlob:
pm_tweets = api.ricerca("India", conteggio=10)Infine, possiamo stampare il testo di ogni Tweet e il sentiment ad esso associato:
per tweet in pm_tweets:stampa (tweet.testo)
analisi = TextBlob(tweet.testo)
stampa(analisi.sentimento)
Una volta eseguito lo script sopra, inizieremo a ricevere le ultime 10 menzioni della query menzionata e ogni tweet verrà analizzato per il valore del sentimento. Ecco l'output che abbiamo ricevuto per lo stesso:

Nota che potresti anche creare un bot di analisi del sentiment in streaming anche con TextBlob e Tweepy. Tweepy consente di stabilire una connessione di streaming websocket con l'API di Twitter e consente di trasmettere i dati di Twitter in tempo reale.
Conclusione
In questa lezione, abbiamo esaminato un eccellente pacchetto di analisi testuale che ci consente di analizzare sentimenti testuali e molto altro. TextBlob è popolare per il modo in cui ci consente di lavorare semplicemente con dati testuali senza il fastidio di chiamate API complesse. Abbiamo anche integrato Tweepy per utilizzare i dati di Twitter. Possiamo facilmente modificare l'utilizzo in un caso d'uso in streaming con lo stesso pacchetto e pochissime modifiche nel codice stesso.
Per favore condividi il tuo feedback liberamente sulla lezione su Twitter con @linuxhint e @sbmaggarwal (sono io!).


