20 esempi imbarazzanti
Esistono molti strumenti di utilità nel sistema operativo Linux per cercare e generare un report da dati di testo o file. L'utente può facilmente eseguire molti tipi di attività di ricerca, sostituzione e generazione di report utilizzando i comandi awk, grep e sed. awk non è solo un comando. È un linguaggio di scripting che può essere utilizzato sia dal terminale che dal file awk. Supporta la variabile, l'istruzione condizionale, l'array, i loop ecc. come altri linguaggi di scripting. Può leggere qualsiasi contenuto di file riga per riga e separare i campi o le colonne in base a un delimitatore specifico. Supporta anche l'espressione regolare per la ricerca di stringhe particolari nel contenuto di testo o nel file e intraprende azioni se viene trovata una corrispondenza. Come puoi usare il comando e lo script awk è mostrato in questo tutorial usando 20 esempi utili.
Contenuti:
- awk con printf
- imbarazzante dividere su uno spazio bianco
- awk per cambiare il delimitatore
- awk con dati delimitati da tabulazioni
- awk con dati CSV
- regex imbarazzante
- regex insensibile alle maiuscole e minuscole
- awk con nf (numero di campi) variabile
- awk gensub() funzione
- awk con la funzione rand()
- awk funzione definita dall'utente
- imbarazzante se
- variabili awk
- array awk
- ciclo imbarazzante
- awk per stampare la prima colonna
- awk per stampare l'ultima colonna
- awk con grep
- awk con il file di script bash
- awk con sed
Usare awk con printf
printf() la funzione viene utilizzata per formattare qualsiasi output nella maggior parte dei linguaggi di programmazione. Questa funzione può essere utilizzata con awk comando per generare diversi tipi di output formattati. comando awk utilizzato principalmente per qualsiasi file di testo. Crea un file di testo chiamato dipendente.TXT con il contenuto indicato di seguito dove i campi sono separati da tab ('\t').
dipendente.TXT
1001 Giovanni sena 400001002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Liver 70000
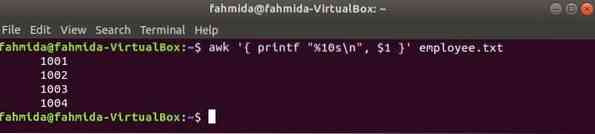
Il seguente comando awk leggerà i dati da dipendente.TXT file riga per riga e stampa il primo file dopo la formattazione. Qui, "%10s\n” significa che l'output sarà lungo 10 caratteri. Se il valore dell'output è inferiore a 10 caratteri, gli spazi verranno aggiunti all'inizio del valore.
$ awk ' printf "%10s\n", $1 ' dipendente.TXTProduzione:
Vai ai contenuti
imbarazzante dividere su uno spazio bianco
Il separatore di parole o di campo predefinito per dividere qualsiasi testo è lo spazio bianco. Il comando awk può accettare il valore del testo come input in vari modi. Il testo di input viene passato da eco comando nel seguente esempio. Il testo, 'mi piace programmare' sarà diviso per separatore predefinito, spazio, e la terza parola verrà stampata come output.
$ echo 'Mi piace programmare' | awk ' stampa $3 'Produzione:

Vai ai contenuti
awk per cambiare il delimitatore
Il comando awk può essere usato per cambiare il delimitatore per qualsiasi contenuto di file. Supponiamo di avere un file di testo chiamato Telefono.TXT con il seguente contenuto dove ':' è usato come separatore di campo del contenuto del file.
Telefono.TXT
+123:334:889:778+880:1855:456:907
+9:7777:38644:808
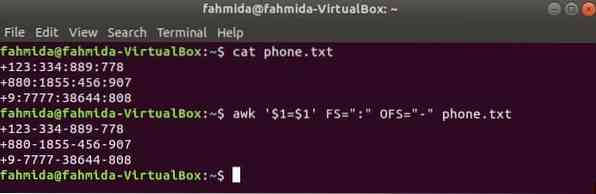
Esegui il seguente comando awk per cambiare il delimitatore, ':' di '-' al contenuto del file, Telefono.TXT.
$ gatto telefono.TXT$ awk '$1=$1' FS=":" OFS="-" telefono.TXT
Produzione:
Vai ai contenuti
awk con dati delimitati da tabulazioni
Il comando awk ha molte variabili integrate che vengono utilizzate per leggere il testo in modi diversi. Due di loro sono FS e OFS. FS è il separatore del campo di input e OFS è variabile separatore di campo di output. Gli usi di queste variabili sono mostrati in questa sezione. Creare un tab file separato denominato ingresso.TXT con il seguente contenuto per testare gli usi di FS e OFS variabili.
Ingresso.TXT
Lato client: linguaggio di scriptingLato server linguaggio di scripting
Server di database
Server web
Utilizzo della variabile FS con tab
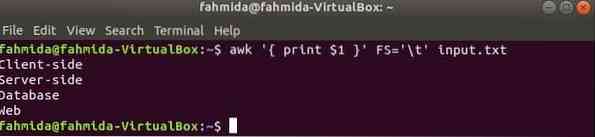
Il seguente comando dividerà ogni riga di ingresso.TXT file basato sulla scheda ('\t') e stampa il primo campo di ogni riga.
$ awk ' print $1 ' FS='\t' input.TXTProduzione:
Utilizzo della variabile OFS con tab
Il seguente comando awk stamperà il 9questo e 5questo campi di 'ls -l' output del comando con separatore di tabulazione dopo aver stampato il titolo della colonna “Nome" e "Dimensione". Qui, OFS la variabile viene utilizzata per formattare l'output da una scheda.
$ ls -l$ ls -l | awk -v OFS='\t' 'BEGIN printf "%s\t%s\n", "Nome", "Dimensione" print $9,$5'
Produzione:

Vai ai contenuti
awk con dati CSV
Il contenuto di qualsiasi file CSV può essere analizzato in più modi usando il comando awk. Crea un file CSV denominato 'cliente.csv' con il seguente contenuto per applicare il comando awk.
cliente.TXT
ID, nome, e-mail, telefono1, Sophia, [e-mail protetta], (862) 478-7263
2, Amelia, [email protetta], (530) 764-8000
3, Emma, [e-mail protetta], (542) 986-2390
Lettura di un singolo campo del file CSV
'-F' l'opzione viene utilizzata con il comando awk per impostare il delimitatore per dividere ogni riga del file. Il seguente comando awk stamperà il nome campo di il cliente.csv file.
$ gatto cliente.csv$ awk -F "," 'stampa $2' cliente.csv
Produzione: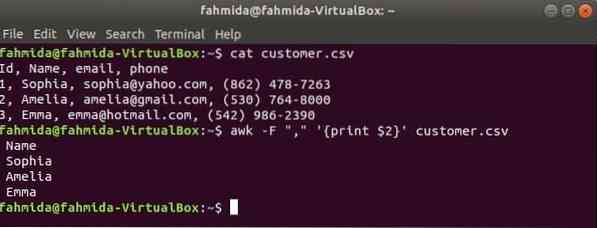
Leggere più campi combinando con altro testo
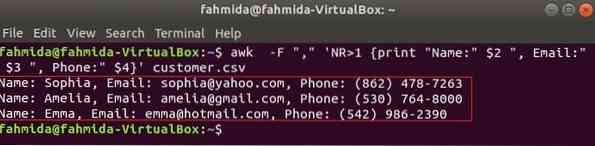
Il seguente comando stamperà tre campi di cliente.csv combinando il testo del titolo, Nome, email e telefono. La prima riga del cliente.csv il file contiene il titolo di ogni campo. NR variabile contiene il numero di riga del file quando il comando awk analizza il file. In questo esempio, il NR la variabile viene utilizzata per omettere la prima riga del file. L'output mostrerà il 2nd, 3rd e 4questo campi di tutte le righe tranne la prima riga.
$ awk -F "," 'NR>1 print "Nome:" $2 ", Email:" $3 ", Telefono:" $4' cliente.csvProduzione:
Lettura di file CSV utilizzando uno script awk
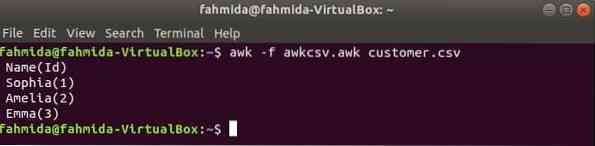
Lo script awk può essere eseguito eseguendo il file awk. Come puoi creare un file awk ed eseguire il file è mostrato in questo esempio. Crea un file chiamato awkcsv.awk con il seguente codice. INIZIO la parola chiave è usata nello script per informare il comando awk di eseguire lo script del INIZIO parte prima di eseguire altre attività. Qui, separatore di campo (FS) viene utilizzato per definire il delimitatore di divisione e 2nd e 1sto i campi verranno stampati in base al formato utilizzato nella funzione printf().
awkcsv.awkINIZIA FS = "," printf "%5s(%s)\n", $2,$1
Correre awkcsv.awk file con il contenuto di il cliente.csv file con il seguente comando.
$ awk -f awkcsv.cliente imbarazzante.csvProduzione:
Vai ai contenuti
regex imbarazzante
L'espressione regolare è un modello che viene utilizzato per cercare qualsiasi stringa in un testo. Diversi tipi di complicate attività di ricerca e sostituzione possono essere eseguite molto facilmente utilizzando l'espressione regolare. Alcuni semplici usi dell'espressione regolare con il comando awk sono mostrati in questa sezione.
Set di caratteri corrispondentiIl seguente comando corrisponderà alla parola Sciocco o bool o Freddo con la stringa di input e stampa se la parola trova. Qui, Bambola non corrisponderà e non stamperà.
$ printf "Fool\nCool\nBambola\nbool" | awk '/[FbC]ool/'Produzione:

Stringa di ricerca all'inizio della riga
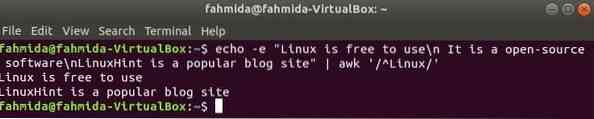
'^' il simbolo viene utilizzato nell'espressione regolare per cercare qualsiasi modello all'inizio della riga. 'Linux' la parola verrà cercata all'inizio di ogni riga del testo nell'esempio seguente. Qui, due righe iniziano con il testo, "Linux"' e quelle due righe verranno mostrate nell'output.
$ echo -e "Linux è gratuito\n È un software open-source\nLinuxHint èun popolare sito di blog" | awk '/^Linux/'
Produzione:
Ricerca stringa alla fine della riga
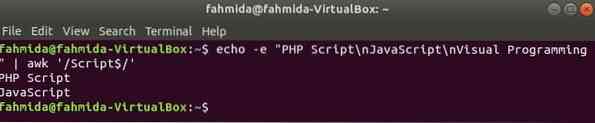
'$' il simbolo viene utilizzato nell'espressione regolare per cercare qualsiasi motivo alla fine di ogni riga del testo. 'sceneggiatura'la parola viene cercata nell'esempio seguente. Qui, due righe contengono la parola, sceneggiatura alla fine della linea.
$ echo -e "Script PHP\nJavaScript\nProgrammazione visiva" | awk '/Script$/'Produzione:
Ricerca omettendo un particolare set di caratteri
'^' il simbolo indica l'inizio del testo quando viene utilizzato davanti a qualsiasi schema di corde ('/^… /') o prima di qualsiasi set di caratteri dichiarato da ^[… ]. Se la '^' il simbolo viene utilizzato all'interno della terza parentesi, [^... ] quindi il set di caratteri definito all'interno della parentesi verrà omesso al momento della ricerca. Il seguente comando cercherà qualsiasi parola che non inizi con 'F' ma termina con 'ool'. Freddo e bool verrà stampato in base al modello e ai dati di testo.
$ printf "Fool\nCool\nBambola\nbool" | awk '/[^F]ool/'Produzione:

Vai ai contenuti
regex insensibile alle maiuscole e minuscole
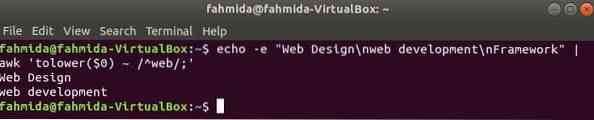
Per impostazione predefinita, l'espressione regolare esegue la ricerca con distinzione tra maiuscole e minuscole durante la ricerca di qualsiasi modello nella stringa. La ricerca senza distinzione tra maiuscole e minuscole può essere eseguita con il comando awk con l'espressione regolare. Nel seguente esempio, ridurre() la funzione viene utilizzata per eseguire ricerche senza distinzione tra maiuscole e minuscole. Qui, la prima parola di ogni riga del testo di input verrà convertita in minuscolo usando ridurre() funzione e corrispondenza con il modello di espressione regolare. toupper() la funzione può essere utilizzata anche per questo scopo, in questo caso, il modello deve essere definito da tutte lettere maiuscole. Il testo definito nell'esempio seguente contiene la parola di ricerca, 'ragnatela' in due righe che verranno stampate come output.
$ echo -e "Web Design\nsviluppo web\nFramework" | awk 'tolower($0) ~ /^web/;'Produzione:
Vai ai contenuti
awk con variabile NF (numero di campi)
NF èuna variabile incorporata del comando awk cheèusata per contare il numero totale di campi in ogni riga del testo di input. Crea qualsiasi file di testo con più righe e più parole. l'ingresso.TXT qui viene utilizzato il file creato nell'esempio precedente.
Utilizzo di NF dalla riga di comando
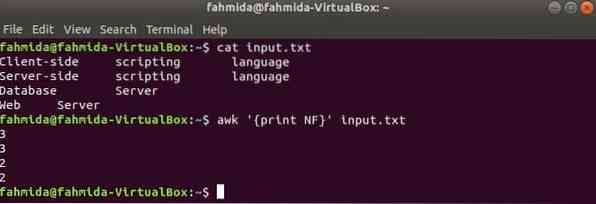
Qui, il primo comando viene utilizzato per visualizzare il contenuto di ingresso.TXT file e il secondo comando viene utilizzato per mostrare il numero totale di campi in ogni riga del file utilizzando NF variabile.
$ ingresso gatto.TXT$ awk 'print NF' input.TXT
Produzione:
Utilizzo di NF nel file awk
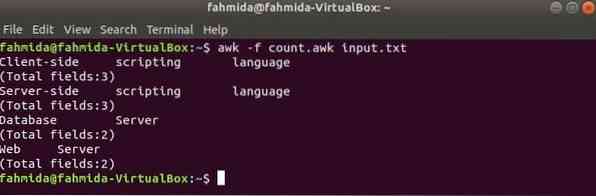
Crea un file awk chiamato contare.awk con lo script indicato di seguito. Quando questo script verrà eseguito con qualsiasi dato di testo, ogni contenuto di riga con i campi totali verrà stampato come output.
contare.awk
stampa $0print "[Totale campi:" NF "]"
Esegui lo script con il seguente comando.
$ awk -f conteggio.input imbarazzante.TXTProduzione:
Vai ai contenuti
awk gensub() funzione
getsub() è una funzione di sostituzione che viene utilizzata per cercare stringhe in base a un particolare delimitatore o modello di espressione regolare. Questa funzione è definita in 'stupido' pacchetto che non è installato di default. La sintassi per questa funzione è riportata di seguito. Il primo parametro contiene il modello di espressione regolare o delimitatore di ricerca, il secondo parametro contiene il testo sostitutivo, il terzo parametro indica come verrà eseguita la ricerca e l'ultimo parametro contiene il testo in cui verrà applicata questa funzione.
Sintassi:
gensub(regexp, sostituzione, come [, target])Esegui il seguente comando per installare gawk pacchetto per l'utilizzo getsub() funzione con il comando awk.
$ sudo apt-get install gawkCrea un file di testo chiamato 'informazioni sulle vendite.TXT' con il seguente contenuto per mettere in pratica questo esempio. Qui, i campi sono separati da una scheda.
informazioni sulle vendite.TXT
lun 700000mar 800000
mer 750000
gio 200000
ven 430000
Sab 820000
Eseguire il seguente comando per leggere i campi numerici del of informazioni sulle vendite.TXT archivia e stampa il totale di tutte le vendite. Qui, il terzo parametro, 'G' indica la ricerca globale. Ciò significa che il modello verrà cercato nell'intero contenuto del file.
$ awk ' x=gensub("\t","","G",$2); printf x "+" END print 0 ' info vendite.txt | bc -lProduzione:

Vai ai contenuti
awk con la funzione rand()
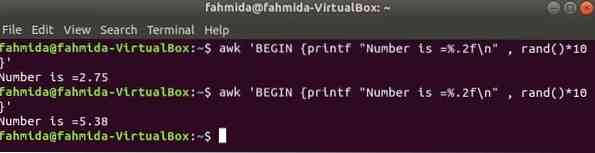
rand() la funzione viene utilizzata per generare qualsiasi numero casuale maggiore di 0 e minore di 1. Quindi, genererà sempre un numero frazionario inferiore a 1. Il seguente comando genererà un numero casuale frazionario e moltiplicherà il valore con 10 per ottenere un numero maggiore di 1. Verrà stampato un numero frazionario con due cifre dopo la virgola decimale per l'applicazione della funzione printf(). Se esegui più volte il seguente comando, otterrai un output diverso ogni volta.
$ awk 'BEGIN printf "Il numero è =%.2f\n" , rand()*10'Produzione:
Vai ai contenuti
awk funzione definita dall'utente
Tutte le funzioni utilizzate negli esempi precedenti sono funzioni integrate. Ma puoi dichiarare una funzione definita dall'utente nel tuo script awk per fare qualsiasi compito particolare. Supponiamo di voler creare una funzione personalizzata per calcolare l'area di un rettangolo. Per eseguire questa attività, crea un file denominato 'la zona.awk'con il seguente script. In questo esempio, una funzione definita dall'utente denominata la zona() è dichiarato nello script che calcola l'area in base ai parametri di input e restituisce il valore dell'area. getline il comando viene utilizzato qui per ricevere input dall'utente.
la zona.awk
# Calcola areaarea della funzione (altezza, larghezza)
ritorno altezza*larghezza
# Avvia l'esecuzione
INIZIO
print "Inserisci il valore dell'altezza:"
getline h < "-"
print "Inserisci il valore della larghezza:"
getline w < "-"
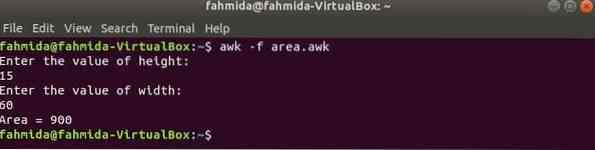
print "Area = " area(h,w)
Esegui lo script.
$ awk -f area.awkProduzione:
Vai ai contenuti
awk se esempio
awk supporta le istruzioni condizionali come altri linguaggi di programmazione standard. In questa sezione vengono mostrati tre tipi di istruzioni if utilizzando tre esempi. Crea un file di testo chiamato elementi.TXT con il seguente contenuto.
elementi.TXT
HDD Samsung $ 100Mouse A4Tech
Stampante HP $ 200
Semplice se esempio:
il seguente comando leggerà il contenuto del elementi.TXT file e controllare il 3rd valore del campo in ogni riga. Se il valore è vuoto, stamperà un messaggio di errore con il numero di riga.
$ awk ' if ($3 == "") print "Il campo del prezzo è mancante nella riga " NR ' elementi.TXTProduzione:
esempio if-else:
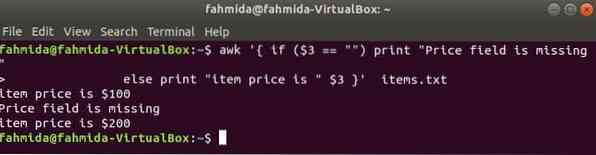
Il seguente comando stamperà il prezzo dell'articolo se il 3rd esiste un campo nella riga, altrimenti verrà stampato un messaggio di errore.
$ awk ' if ($3 == "") print "Manca il campo del prezzo"altrimenti stampa "il prezzo dell'articolo è " $3 ' articoli.TXT
Produzione:
esempio if-else-if:
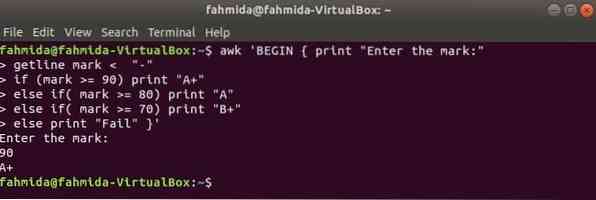
Quando il seguente comando verrà eseguito dal terminale, richiederà input dall'utente. Il valore di input verrà confrontato con ciascuna condizione if finché la condizione non è vera is. Se una qualsiasi condizione diventa vera, stamperà il voto corrispondente. Se il valore di input non corrisponde a nessuna condizione, verrà stampato con esito negativo.
$ awk 'BEGIN print "Inserisci il segno:"getline mark get < "-"
if (segno >= 90) print "A+"
else if(mark >= 80) print "A"
else if(mark >= 70) print "B+"
altrimenti stampa "Fallito" '
Produzione:
Vai ai contenuti
variabili awk
La dichiarazione della variabile awk è simile alla dichiarazione della variabile shell. C'è una differenza nella lettura del valore della variabile. Il simbolo '$' viene utilizzato con il nome della variabile per la variabile shell per leggere il valore. Ma non è necessario utilizzare '$' con la variabile awk per leggere il valore.
Usando una variabile semplice:
Il seguente comando dichiarerà una variabile denominata 'luogo' e un valore stringa è assegnato a quella variabile. Il valore della variabile viene stampato nell'istruzione successiva.
$ awk 'BEGIN site="LinuxHint.com"; stampa sito'Produzione:

Utilizzo di una variabile per recuperare i dati da un file
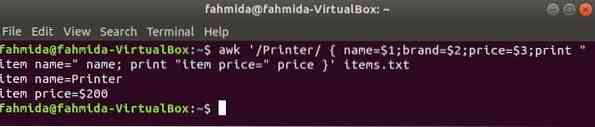
Il seguente comando cercherà la parola 'Stampante' nel file elementi.TXT. Se una qualsiasi riga del file inizia con 'Stampante' allora memorizzerà il valore di 1sto, 2nd e 3rd campi in tre variabili. nome e prezzo le variabili verranno stampate.
$ awk '/Stampante/ nome=$1;marca=$2;prezzo=$3;print "nome oggetto=" nome;stampa "prezzo articolo=" prezzo ' articoli.TXT
Produzione:
Vai ai contenuti
array awk
Sia gli array numerici che quelli associati possono essere usati in awk. La dichiarazione della variabile array in awk è la stessa di altri linguaggi di programmazione. Alcuni usi degli array sono mostrati in questa sezione.
Matrice associativa:
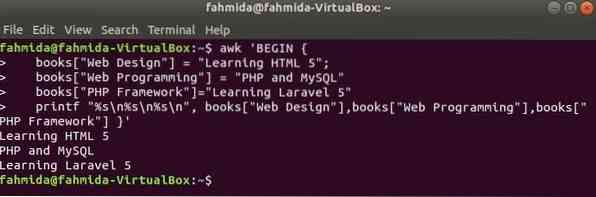
L'indice dell'array sarà qualsiasi stringa per l'array associativo. In questo esempio, viene dichiarato e stampato un array associativo di tre elementi.
$ awk 'INIZIAbooks["Web Design"] = "Imparare HTML 5";
books["Programmazione Web"] = "PHP e MySQL"
libri["PHP Framework"]="Imparare Laravel 5"
printf "%s\n%s\n%s\n", libri["Web Design"],libri["Programmazione web"],
libri["Framework PHP"] '
Produzione:
Matrice numerica:
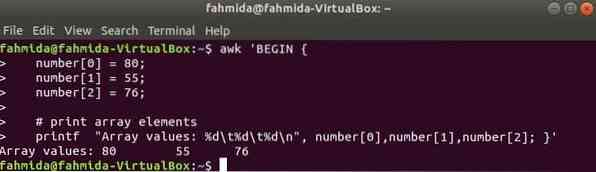
Un array numerico di tre elementi viene dichiarato e stampato separando tab.
$ awk 'INIZIAnumero[0] = 80;
numero[1] = 55;
numero[2] = 76;
# stampa gli elementi dell'array
printf "Valori array: %d\t%d\t%d\n", numero[0],numero[1],numero[2]; '
Produzione:
Vai ai contenuti
ciclo imbarazzante
Tre tipi di loop sono supportati da awk. Gli usi di questi loop sono mostrati qui usando tre esempi.
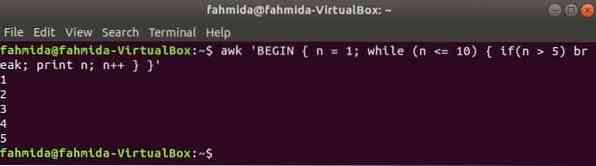
Mentre il ciclo:
Il ciclo while utilizzato nel comando seguente itera per 5 volte e uscirà dal ciclo per l'istruzione break.
$ awk 'BEGIN n = 1; mentre (n <= 10) if(n > 5) rottura; stampa n; n++ 'Produzione:
Per ciclo:
For loop utilizzato nel seguente comando awk calcolerà la somma da 1 a 10 e stamperà il valore.
$ awk 'BEGIN somma=0; per (n = 1; n <= 10; n++) sum=sum+n; print sum 'Produzione:

Ciclo da fare mentre:
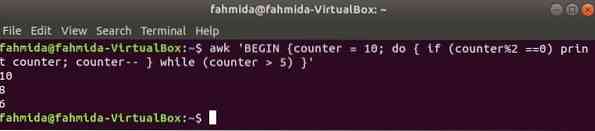
un ciclo do-while del seguente comando stamperà tutti i numeri pari da 10 a 5.
$ awk 'BEGIN contatore = 10; do if (counter%2 ==0) print contatore; contro--mentre (contatore > 5) '
Produzione:
Vai ai contenuti
awk per stampare la prima colonna
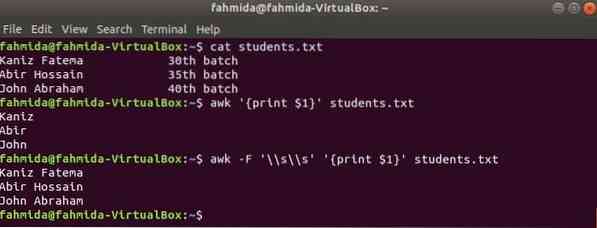
La prima colonna di qualsiasi file può essere stampata usando la variabile $1 in awk. Ma se il valore della prima colonna contiene più parole, viene stampata solo la prima parola della prima colonna. Utilizzando un delimitatore specifico, la prima colonna può essere stampata correttamente. Crea un file di testo chiamato studenti.TXT con il seguente contenuto. Qui, la prima colonna contiene il testo di due parole.
Studenti.TXT
Kaniz Fatema 30questo lottoAbir Hossain 35questo lotto
John Abraham 40questo lotto
Esegui il comando awk senza alcun delimitatore. Verrà stampata la prima parte della prima colonna.
$ awk 'print $1' studenti.TXTEsegui il comando awk con il seguente delimitatore. Verrà stampata l'intera parte della prima colonna.
$ awk -F '\\s\\s' 'print $1' studenti.TXTProduzione:
Vai ai contenuti
awk per stampare l'ultima colonna
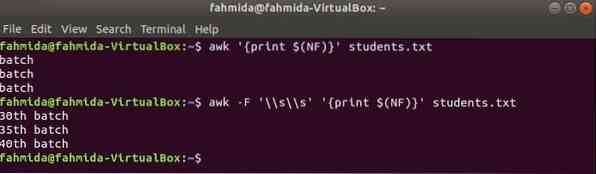
$(NF) variabile può essere utilizzata per stampare l'ultima colonna di qualsiasi file. I seguenti comandi awk stamperanno l'ultima parte e l'intera parte dell'ultima colonna di Gli studenti.TXT file.
$ awk 'print $(NF)' studenti.TXT$ awk -F '\\s\\s' 'print $(NF)' studenti.TXT
Produzione:
Vai ai contenuti
awk con grep
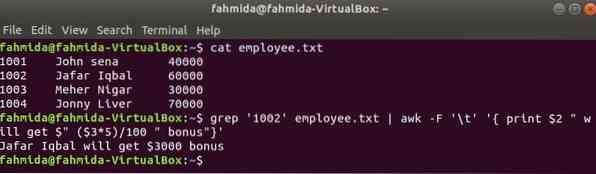
grep è un altro utile comando di Linux per cercare contenuto in un file basato su qualsiasi espressione regolare. L'esempio seguente mostra come i comandi awk e grep possono essere usati insieme. grep comando viene utilizzato per cercare informazioni sull'ID dipendente, '1002' a partire dal il dipendente.TXT file. L'output del comando grep verrà inviato a awk come dati di input. Il bonus del 5% verrà conteggiato e stampato in base allo stipendio del dipendente id, '1002' dal comando awkk.
$ cat dipendente.TXT$ grep '1002' dipendente.txt | awk -F '\t' ' print $2 " otterrà $" ($3*5)/100 " bonus"'
Produzione:
Vai ai contenuti
awk con file BASH
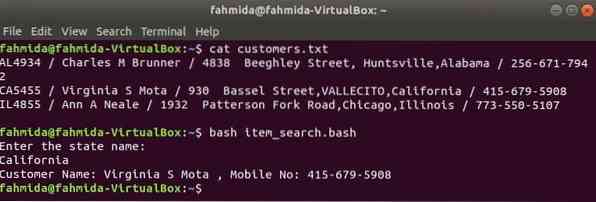
Come altri comandi Linux, anche il comando awk può essere utilizzato in uno script BASH. Crea un file di testo chiamato clienti.TXT con il seguente contenuto. Ogni riga di questo file contiene informazioni su quattro campi. Questi sono l'ID del cliente, il nome, l'indirizzo e il numero di cellulare che sono separati da '/'.
clienti.TXT
AL4934 / Charles M Brunner / 4838 Beeghley Street, Huntsville, Alabama / 256-671-7942CA5455 / Virginia S Mota / 930 Bassel Street,VALLECITO,California / 415-679-5908
IL4855/Ann A Neale / 1932 Patterson Fork Road,Chicago,Illinois / 773-550-5107
Crea un file bash chiamato articolo_ricerca.bash con il seguente script. Secondo questo script, il valore dello stato verrà preso dall'utente e cercato in i clienti.TXT file per grep comando e passato al comando awk come input. Il comando Awk leggerà 2nd e 4questo campi di ogni riga. Se il valore di input corrisponde a qualsiasi valore di stato di clienti.TXT file quindi stamperà quello del cliente customer nome e numero di cellulare, in caso contrario, stamperà il messaggio “Nessun cliente trovato".
articolo_ricerca.bash
#!/bin/bashecho "Inserisci il nome dello stato:"
leggi lo stato
clienti='grep "$stato" clienti.txt | awk -F "/" 'print "Nome cliente:" $2, ",
N. cellulare:" $4''
if [ "$clienti" != "" ]; poi
echo $clienti
altro
echo "Nessun cliente trovato"
fi
Esegui i seguenti comandi per mostrare gli output.
$ clienti gatto.TXT$ bash item_search.bash
Produzione:
Vai ai contenuti
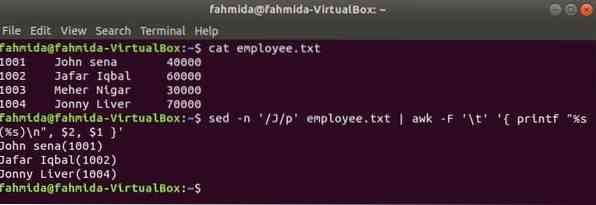
awk con sed
Un altro utile strumento di ricerca di Linux è sed. Questo comando può essere utilizzato sia per cercare che per sostituire il testo di qualsiasi file. L'esempio seguente mostra l'uso del comando awk con sed comando. Qui, il comando sed cercherà tutti i nomi dei dipendenti che iniziano con "J' e passa al comando awk come input. awk stamperà dipendente nome e ID dopo la formattazione.
$ dipendente gatto.TXT$ sed -n '/J/p' impiegato.txt | awk -F '\t' ' printf "%s(%s)\n", $2, $1 '
Produzione:
Vai ai contenuti
Conclusione:
È possibile utilizzare il comando awk per creare diversi tipi di report basati su dati tabulari o delimitati dopo aver filtrato i dati correttamente. Spero che sarai in grado di imparare come funziona il comando awk dopo aver praticato gli esempi mostrati in questo tutorial.


