Parte 1: Configurazione di un singolo nodo
Oggi, archiviare elettronicamente i tuoi documenti o dati su un dispositivo di archiviazione è facile e veloce ed è anche relativamente economico. In uso è un riferimento al nome di file che ha lo scopo di descrivere di cosa tratta il documento. In alternativa, i dati vengono conservati in un Database Management System (DBMS) come PostgreSQL, MariaDB o MongoDB per citare solo alcune opzioni. Diversi supporti di archiviazione sono collegati al computer localmente o in remoto, come chiavetta USB, disco rigido interno o esterno, NAS (Network Attached Storage), Cloud Storage o basati su GPU/Flash, come in un Nvidia V100 [10].
Al contrario, il processo inverso, trovare i documenti giusti in una raccolta di documenti, è piuttosto complesso. Richiede principalmente il rilevamento del formato del file senza errori, l'indicizzazione del documento e l'estrazione dei concetti chiave (classificazione del documento). È qui che entra in gioco il framework Apache Solr. Offre un'interfaccia pratica per eseguire i passaggi menzionati: creazione di un indice di documenti, accettazione di query di ricerca, esecuzione della ricerca effettiva e restituzione di un risultato di ricerca. Apache Solr costituisce quindi il nucleo per una ricerca efficace su un database o un silo di documenti.
In questo articolo imparerai come funziona Apache Solr, come impostare un singolo nodo, indicizzare i documenti, fare una ricerca e recuperare il risultato.
Gli articoli di follow-up si basano su questo e, in essi, discutiamo altri casi d'uso più specifici come l'integrazione di un DBMS PostgreSQL come origine dati o il bilanciamento del carico su più nodi.
Informazioni sul progetto Apache Solr
Apache Solr è un framework per motori di ricerca basato sul potente search index server Lucene [2]. Scritto in Java, è gestito sotto l'egida della Apache Software Foundation (ASF) [6]. È disponibile gratuitamente con la licenza Apache 2.
L'argomento "Ritrova documenti e dati" svolge un ruolo molto importante nel mondo del software e molti sviluppatori lo affrontano intensamente. Il sito web Awesomeopensource [4] elenca più di 150 progetti open-source dei motori di ricerca. All'inizio del 2021, ElasticSearch [8] e Apache Solr/Lucene sono i due cani migliori quando si tratta di cercare set di dati più grandi. Lo sviluppo del tuo motore di ricerca richiede molte conoscenze, Frank lo fa con la libreria AdvaS Advanced Search [3] basata su Python dal 2002.
Configurazione di Apache Solr:
L'installazione e il funzionamento di Apache Solr non sono complicati, sono semplicemente tutta una serie di passaggi che devono essere eseguiti da te. Attendere circa 1 ora per il risultato della prima query di dati. Inoltre, Apache Solr non è solo un progetto per hobby, ma viene utilizzato anche in un ambiente professionale. Pertanto, l'ambiente del sistema operativo scelto è progettato per un uso a lungo termine.
Come ambiente di base per questo articolo, usiamo Debian GNU/Linux 11, che è l'imminente rilascio di Debian (all'inizio del 2021) e dovrebbe essere disponibile a metà del 2021. Per questo tutorial, ci aspettiamo che tu l'abbia già installato, come sistema nativo, in una macchina virtuale come VirtualBox o in un container AWS.
Oltre ai componenti di base, è necessario installare sul sistema i seguenti pacchetti software:
- Arricciare
- Predefinito-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (una libreria del progetto Apache Tika [11])
Questi pacchetti sono componenti standard di Debian GNU/Linux. Se non ancora installati, puoi post-installarli in una volta sola come utente con diritti di amministratore, ad esempio root o tramite sudo, mostrato come segue:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaDopo aver preparato l'ambiente, il secondo passo è l'installazione di Apache Solr. Al momento, Apache Solr non è disponibile come pacchetto Debian normale. Pertanto, è necessario recuperare Apache Solr 8.8 dalla sezione download del sito web del progetto [9] prima. Usa il comando wget di seguito per salvarlo nella directory /tmp del tuo sistema:
$ wget -O /tmp https://downloads.apache.org/lucene/solr/8.8.0/sol-8.8.0.tgzL'opzione -O accorcia -output-document e fa in modo che wget memorizzi il tar recuperato.gz nella directory data. L'archivio ha una dimensione di circa 190M. Quindi, scompattare l'archivio nella directory /opt usando tar. Di conseguenza, troverai due sottodirectory: /opt/solr e /opt/solr-8.8.0, mentre /opt/solr è impostato come collegamento simbolico a quest'ultimo. Apache Solr viene fornito con uno script di installazione che viene eseguito successivamente, è il seguente:
# /opt/solr-8.8.0/bin/install_solr_service.shCiò si traduce nella creazione dell'utente Linux che solr viene eseguito nel servizio Solr più la sua home directory in /var/solr stabilisce il servizio Solr, aggiunto con i suoi nodi corrispondenti e avvia il servizio Solr sulla porta 8983. Questi sono i valori predefiniti. Se non sei soddisfatto, puoi modificarli durante l'installazione o anche in seguito poiché lo script di installazione accetta le opzioni corrispondenti per le regolazioni della configurazione. Ti consigliamo di dare un'occhiata alla documentazione di Apache Solr riguardo a questi parametri.
Il software Solr è organizzato nelle seguenti directory:
- bidone
contiene i binari e i file di Solr per eseguire Solr come servizio - contributo
librerie Solr esterne come il gestore di importazione dati e le librerie Lucene - dist
librerie interne Solr - documenti
collegamento alla documentazione Solr disponibile online - esempio
set di dati di esempio o diversi casi d'uso/scenari - licenze
licenze software per i vari componenti Solr - server
file di configurazione del server, come server/etc per servizi e porte
Più in dettaglio, puoi leggere su queste directory nella documentazione di Apache Solr [12].
Gestione di Apache Solr:
Apache Solr viene eseguito come servizio in background. Puoi avviarlo in due modi, utilizzando systemctl (prima riga) come utente con autorizzazioni amministrative o direttamente dalla directory Solr (seconda riga). Elenchiamo di seguito entrambi i comandi del terminale:
# systemctl start solr$ solr/bin/solr start
L'arresto di Apache Solr viene eseguito in modo simile:
# systemctl stop solr$ solr/bin/solr stop
Lo stesso vale per il riavvio del servizio Apache Solr:
# systemctl riavvia solr$ solr/bin/solr riavvio
Inoltre, lo stato del processo Apache Solr può essere visualizzato come segue:
# systemctl status solr$ solr/bin/solr status
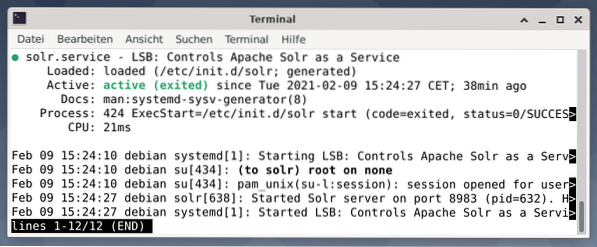
L'output elenca il file di servizio che è stato avviato, sia il timestamp corrispondente che i messaggi di registro. La figura seguente mostra che il servizio Apache Solr è stato avviato sulla porta 8983 con il processo 632. Il processo è stato eseguito correttamente per 38 minuti.
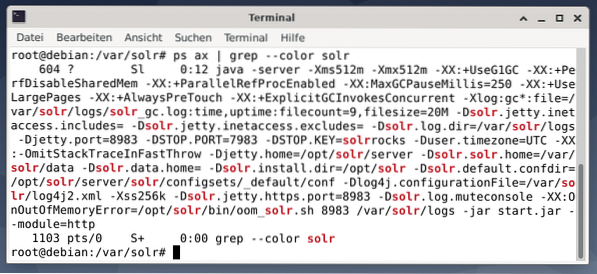
Per vedere se il processo Apache Solr è attivo, puoi anche fare un controllo incrociato usando il comando ps in combinazione con grep. Questo limita l'output di ps a tutti i processi Apache Solr attualmente attivi currently.
# ps ascia | grep --color solrLa figura seguente lo dimostra per un singolo processo. Viene visualizzata la chiamata di Java che è accompagnata da un elenco di parametri, ad esempio porte di utilizzo della memoria (512M) da ascoltare su 8983 per query, 7983 per richieste di arresto e tipo di connessione (http).
Aggiunta di utenti:
I processi Apache Solr vengono eseguiti con un utente specifico chiamato solr. Questo utente è utile nella gestione dei processi Solr, nel caricamento dei dati e nell'invio delle richieste. Al momento della configurazione, l'utente solr non dispone di una password e dovrebbe averne una per accedere per procedere ulteriormente. Imposta una password per l'utente solr come utente root, viene mostrata come segue:
# passwd solrAmministrazione Solr:
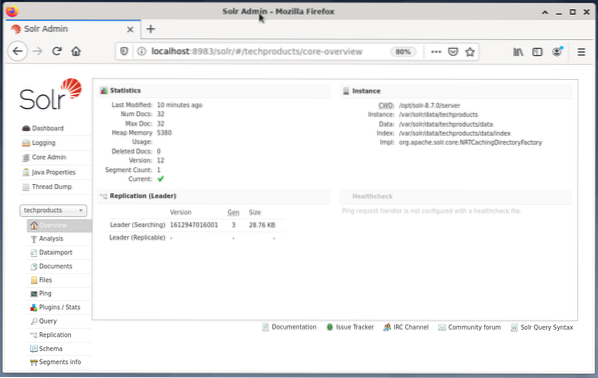
La gestione di Apache Solr viene eseguita utilizzando Solr Dashboard. Questo è accessibile tramite browser Web da http://localhost:8983/solr. La figura seguente mostra la vista principale.
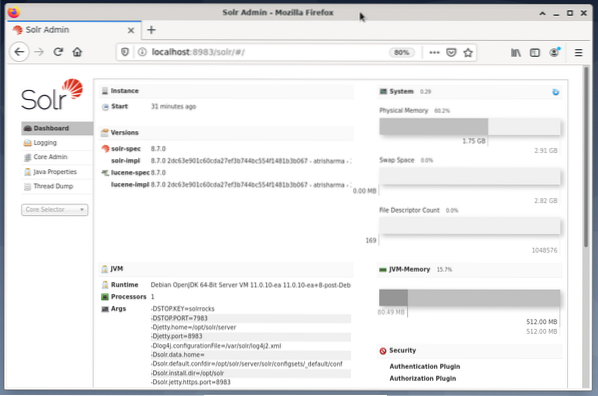
Sulla sinistra, vedi il menu principale che ti porta alle sottosezioni per la registrazione, l'amministrazione dei core Solr, l'installazione di Java e le informazioni sullo stato. Scegli il nucleo desiderato utilizzando la casella di selezione sotto il menu. Sul lato destro del menu, vengono visualizzate le informazioni corrispondenti. La voce del menu Dashboard mostra ulteriori dettagli riguardanti il processo Apache Solr, nonché il carico corrente e l'utilizzo della memoria.
Tieni presente che il contenuto della Dashboard cambia a seconda del numero di core Solr e dei documenti che sono stati indicizzati. Le modifiche interessano sia le voci di menu che le informazioni corrispondenti visibili a destra.
Capire come funzionano i motori di ricerca:
In parole povere, i motori di ricerca analizzano i documenti, li classificano e consentono di effettuare una ricerca in base alla loro categorizzazione. Fondamentalmente, il processo consiste in tre fasi, denominate scansione, indicizzazione e classificazione [13].
strisciare è la prima fase e descrive un processo mediante il quale vengono raccolti contenuti nuovi e aggiornati. Il motore di ricerca utilizza robot noti anche come spider o crawler, da cui il termine scansione per esaminare i documenti disponibili.
La seconda fase si chiama indicizzazione. Il contenuto precedentemente raccolto viene reso ricercabile trasformando i documenti originali in un formato comprensibile dal motore di ricerca search. Parole chiave e concetti vengono estratti e archiviati in database (massicci).
La terza fase si chiama classifica e descrive il processo di ordinamento dei risultati della ricerca in base alla loro pertinenza con una query di ricerca. È comune visualizzare i risultati in ordine decrescente in modo che il risultato che ha la massima rilevanza per la query del ricercatore venga prima.
Apache Solr funziona in modo simile al processo in tre fasi precedentemente descritto. Come il popolare motore di ricerca Google, Apache Solr utilizza una sequenza di raccolta, archiviazione e indicizzazione di documenti da diverse fonti e li rende disponibili/ricercabili quasi in tempo reale.
Apache Solr utilizza diversi modi per indicizzare i documenti, inclusi i seguenti [14]:
- Utilizzo di un gestore di richieste di indice quando si caricano i documenti direttamente su Solr. Questi documenti dovrebbero essere nei formati JSON, XML/XSLT o CSV.
- Utilizzo del gestore della richiesta di estrazione (cella Solr). I documenti devono essere in formato PDF o Office, che sono supportati da Apache Tika.
- Utilizzo del gestore di importazione dati, che trasmette i dati da un database e li cataloga utilizzando i nomi delle colonne. Il gestore di importazione dati recupera i dati da e-mail, feed RSS, dati XML, database e file di testo normale come origini.
Un gestore di query viene utilizzato in Apache Solr quando viene inviata una richiesta di ricerca. Il gestore della query analizza la query data in base allo stesso concetto del gestore dell'indice in modo che corrisponda alla query e ai documenti indicizzati in precedenza. Le partite sono classificate in base alla loro adeguatezza o pertinenza. Di seguito viene mostrato un breve esempio di interrogazione.
Caricamento documenti:
Per semplicità, utilizziamo un set di dati di esempio per il seguente esempio già fornito da Apache Solr. Il caricamento dei documenti viene eseguito come l'utente solr. Il passaggio 1 è la creazione di un nucleo con il nome techproducts (per un numero di articoli tecnologici).
$ solr/bin/solr create -c prodotti tecnologici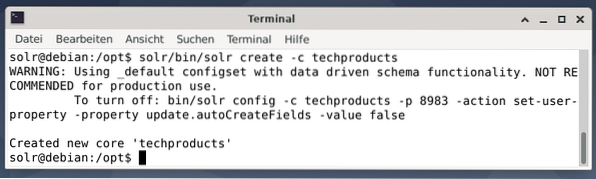
Va tutto bene se vedi il messaggio "Creato nuovo core 'techproducts'". Il passaggio 2 consiste nell'aggiungere dati (dati XML da exampledocs) ai prodotti tecnologici di base creati in precedenza. In uso è il tool post che è parametrizzato da -c (nome del core) e i documenti da caricare.
$ solr/bin/post -c techproducts solr/example/exampledocs/*.xmlCiò risulterà nell'output mostrato di seguito e conterrà l'intera chiamata più i 14 documenti che sono stati indicizzati.
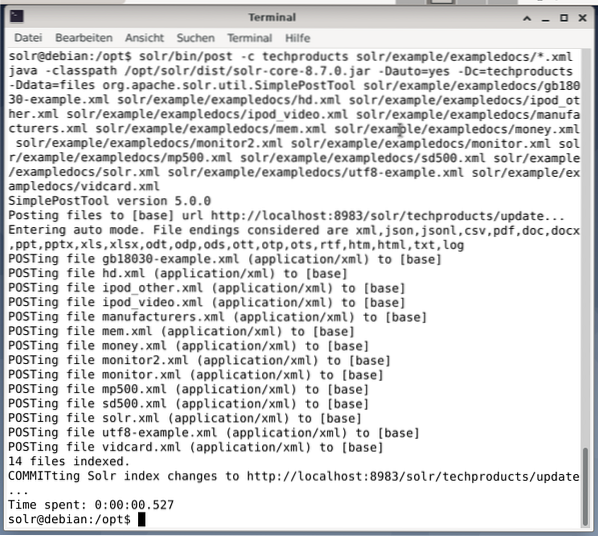
Inoltre, la Dashboard mostra le modifiche. Una nuova voce denominata techproducts è visibile nel menu a discesa sul lato sinistro e il numero di documenti corrispondenti è cambiato sul lato destro. Sfortunatamente, non è possibile una visualizzazione dettagliata dei set di dati grezzi.
Nel caso in cui sia necessario rimuovere il nucleo/raccolta, utilizzare il seguente comando:
$ solr/bin/solr delete -c prodotti tecnologiciInterrogazione dati:
Apache Solr offre due interfacce per interrogare i dati: tramite la Dashboard basata sul Web e la riga di comando. Spiegheremo entrambi i metodi di seguito.
L'invio di query tramite la dashboard di Solr avviene come segue:
- Scegli i prodotti tecnologici del nodo dal menu a tendina.
- Scegli la voce Query dal menu sotto il menu a tendina.
I campi di immissione vengono visualizzati sul lato destro per formulare la query come gestore di richiesta (qt), query (q) e ordinamento (ordinamento). - Scegli il campo di immissione Query e modifica il contenuto della voce da “*:*” a “manu:Belkin”. Ciò limita la ricerca da "tutti i campi con tutte le voci" a "set di dati che hanno il nome Belkin nel campo manu". In questo caso, il nome manu abbrevia il produttore nel set di dati di esempio.
- Quindi, premi il pulsante con Esegui query. Il risultato è una richiesta HTTP stampata in alto e un risultato della query di ricerca in formato dati JSON di seguito.
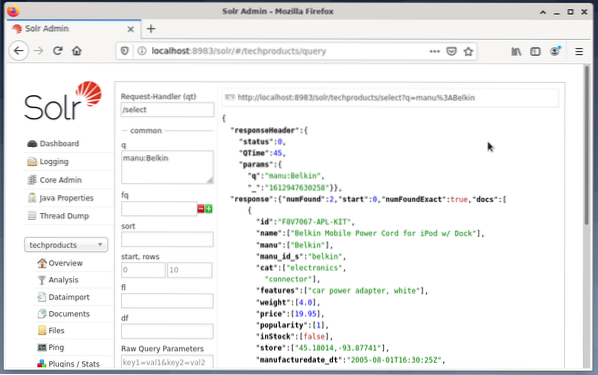
La riga di comando accetta la stessa query della Dashboard. La differenza è che devi conoscere il nome dei campi di query. Per inviare la stessa query come sopra, devi eseguire il seguente comando in un terminale:
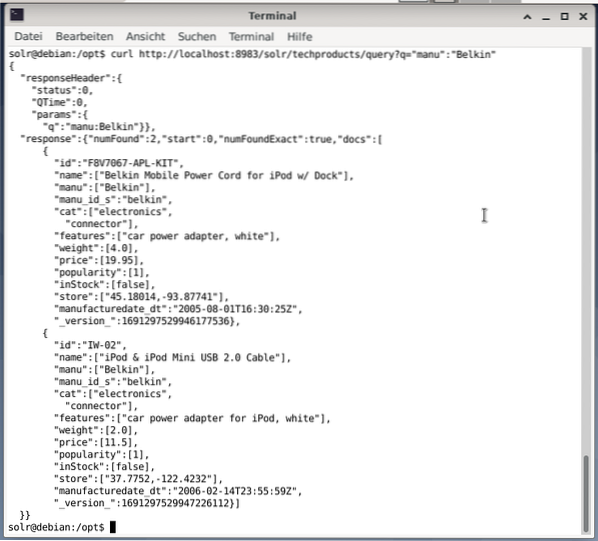
$ curlhttp://localhost:8983/solr/techproducts/query?q=”manu”:”Belkin
L'output è in formato JSON, come mostrato di seguito. Il risultato è costituito da un'intestazione di risposta e dalla risposta effettiva. La risposta è composta da due set di dati.
Avvolgendo:
Congratulazioni! Hai raggiunto la prima fase con successo. L'infrastruttura di base è impostata e hai imparato a caricare e interrogare i documenti.
Il passaggio successivo riguarderà come perfezionare la query, formulare query più complesse e comprendere i diversi moduli Web forniti dalla pagina di query di Apache Solr. Inoltre, discuteremo come post-elaborare il risultato della ricerca utilizzando diversi formati di output come XML, CSV e JSON.
Riguardo agli Autori:
Jacqui Kabeta è un ambientalista, avido ricercatore, formatore e mentore. In diversi paesi africani, ha lavorato nel settore IT e negli ambienti delle ONG.
Frank Hofmann è uno sviluppatore IT, formatore e autore e preferisce lavorare a Berlino, Ginevra e Città del Capo. Coautore del libro sulla gestione dei pacchetti Debian disponibile da dpmb.organizzazione
- [1] Apache Solr, https://lucene.apache.org/solr/
- [2] Libreria di ricerca Lucene, https://lucene.apache.org/
- [3]Ricerca avanzata AdvaS, https://pypi.org/progetto/AdvaS-Ricerca-avanzata/
- [4] I 165 migliori progetti open source dei motori di ricerca, https://awesomeopensource.com/progetti/motore-di-ricerca
- [5] ElasticSearch, https://www.elastico.co/de/elasticsearch/
- [6]Apache Software Foundation (ASF), https://www.apache.org/
- [7]FESS, https://fess.codelibs.organizzazione/indice.html
- [8] ElasticSearch, https://www.elastico.codice/
- [9] Apache Solr, sezione Download, https://lucene.apache.org/solr/downloads.htm
- [10] Nvidia V100, https://www.nvidia.com/it-it/data-center/v100/
- [11] Apache Tika, https://tika.apache.org/
- [12] Layout della directory di Apache Solr, https://lucene.apache.org/solr/guide/8_8/installing-solr.html#directory-layout
- [13] Come funzionano i motori di ricerca: scansione, indicizzazione e posizionamento. La guida per principianti alla SEO https://moz.com/guida-per-principianti-seo/come-funzionano-i-motori-di-ricerca
- [14] Inizia con Apache Solr, https://sematext.com/guides/solr/#:~:text=Solr%20works%20by%20gathering%2C%20storing,con%20huge%20volumes%20of%20data