Chiunque tu chieda come costruire correttamente il software, ti verrà in mente Make come una delle risposte. Sui sistemi GNU/Linux, GNU Make [1] è la versione Open-Source dell'originale Make che è stato rilasciato più di 40 anni fa - nel 1976. Make funziona con un Makefile - un file di testo strutturato con quel nome che può essere meglio descritto come il manuale di costruzione per il processo di costruzione del software. Il Makefile contiene un numero di etichette (chiamate target) e le istruzioni specifiche necessarie per essere eseguite per costruire ogni target.
In parole povere, Make è uno strumento di costruzione. Segue la ricetta dei compiti dal Makefile. Ti consente di ripetere i passaggi in modo automatico anziché digitarli in un terminale (e probabilmente commettere errori durante la digitazione).
Il Listato 1 mostra un Makefile di esempio con i due target “e1” ed “e2” così come i due target speciali “all” e “clean.” L'esecuzione di “make e1” esegue le istruzioni per il target “e1” e crea il file vuoto uno. L'esecuzione di "make e2" fa lo stesso per il target "e2" e crea il file vuoto due. La chiamata di "make all" esegue le istruzioni per il target e1 prima e e2 dopo. Per rimuovere i file uno e due creati in precedenza, è sufficiente eseguire la chiamata "make clean"."
Listato 1
tutti: e1 e2e1:
toccarne uno
e2:
tocca due
pulito:
rm uno due
Esecuzione di make
Il caso comune è che scrivi il tuo Makefile e poi esegui semplicemente il comando "make" o "make all" per costruire il software e i suoi componenti. Tutti i target sono costruiti in ordine seriale e senza alcuna parallelizzazione. Il tempo di costruzione totale è la somma del tempo necessario per costruire ogni singolo obiettivo.
Questo approccio funziona bene per i piccoli progetti, ma richiede molto tempo per i progetti medi e grandi. Questo approccio non è più aggiornato in quanto la maggior parte delle attuali cpu sono dotate di più di un core e consentono l'esecuzione di più di un processo alla volta. Con queste idee in mente, esaminiamo se e come il processo di costruzione può essere parallelizzato. L'obiettivo è semplicemente ridurre i tempi di costruzione.
Miglioramenti
Ci sono alcune opzioni che abbiamo: 1) semplificare il codice, 2) distribuire le singole attività su diversi nodi di calcolo, creare il codice lì e raccogliere il risultato da lì, 3) creare il codice in parallelo su una singola macchina e 4) combinare le opzioni 2 e 3.
L'opzione 1) non è sempre facile. Richiede la volontà di analizzare il runtime dell'algoritmo implementato e la conoscenza del compilatore, i.e., come fa il compilatore a tradurre le istruzioni nel linguaggio di programmazione in istruzioni del processore?.
L'opzione 2) richiede l'accesso ad altri nodi di elaborazione, ad esempio nodi di elaborazione dedicati, macchine inutilizzate o meno utilizzate, macchine virtuali da servizi cloud come AWS o potenza di calcolo a noleggio da servizi come LoadTeam [5]. In realtà, questo approccio viene utilizzato per creare pacchetti software. Debian GNU/Linux usa la cosiddetta rete Autobuilder [17] e RedHat/Fedors usa Koji [18]. Google chiama il suo sistema BuildRabbit ed è perfettamente spiegato nel discorso di Aysylu Greenberg [16]. distcc [2] è un cosiddetto compilatore C distribuito che consente di compilare codice su diversi nodi in parallelo e di impostare il proprio sistema di compilazione.
L'opzione 3 utilizza la parallelizzazione a livello locale. Questa potrebbe essere l'opzione con il miglior rapporto costi-benefici per te, in quanto non richiede hardware aggiuntivo come nell'opzione 2. Il requisito per eseguire Make in parallelo è aggiungere l'opzione -j nella chiamata (abbreviazione di -jobs). Questo specifica il numero di lavori eseguiti contemporaneamente. L'elenco seguente chiede a Make di eseguire 4 lavori in parallelo:
Listato 2
$ make --jobs=4Secondo la legge di Amdahl [23], questo ridurrà il tempo di costruzione di quasi il 50%. Tieni presente che questo approccio funziona bene se i singoli obiettivi non dipendono l'uno dall'altro; per esempio, l'output del target 5 non è richiesto per costruire il target 3.
Tuttavia, c'è un effetto collaterale: l'output dei messaggi di stato per ciascun target Make appare arbitrario e questi non possono più essere chiaramente assegnati a un target. L'ordine di uscita dipende dall'ordine effettivo di esecuzione del lavoro.
Definisci Crea ordine di esecuzione
Ci sono affermazioni che aiutano Make a capire quali obiettivi dipendono l'uno dall'altro? sì! L'esempio Makefile nel Listato 3 dice questo:
* per costruire il target "all", esegui le istruzioni per e1, e2 ed e3
* target e2 richiede la creazione di target e3 prima
Ciò significa che gli obiettivi e1 ed e3 possono essere costruiti in parallelo, prima, quindi e2 segue non appena la costruzione di e3 è completata, infine.
Listato 3
tutti: e1 e2 e3e1:
toccarne uno
e2: e3
tocca due
e3:
tocca tre
pulito:
rm uno due tre
Visualizza le dipendenze di creazione
Lo strumento intelligente make2graph del progetto makefile2graph [19] visualizza le dipendenze Make come un grafico aciclico diretto. Questo aiuta a capire come i diversi target dipendano l'uno dall'altro. Make2graph emette descrizioni di grafici in formato punto che puoi trasformare in un'immagine PNG usando il comando punto dal progetto Graphviz [22]. La chiamata è la seguente:
Listato 4
$ crea tutto -Bnd | make2graph | punto -Tpng -o grafico.pngInnanzitutto, viene chiamato Make con il target "all" seguito dalle opzioni "-B" per costruire incondizionatamente tutti i target, "-n" (abbreviazione di "-dry-run") per fingere di eseguire le istruzioni per target e " -d" ("-debug") per visualizzare le informazioni di debug. L'output viene reindirizzato a make2graph che convoglia il suo output al punto che genera il grafico del file di immagine.png in formato PNG.
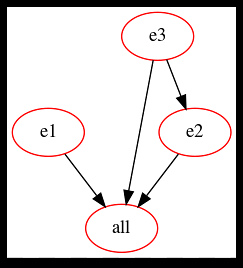
Il grafico delle dipendenze di build per l'elenco 3
Più compilatori e sistemi di compilazione
Come già spiegato sopra, Make è stato sviluppato più di quattro decenni fa. Nel corso degli anni, l'esecuzione di lavori in parallelo è diventata sempre più importante e da allora è cresciuto il numero di compilatori e sistemi di compilazione appositamente progettati per raggiungere un livello più elevato di parallelizzazione. L'elenco degli strumenti include questi:
- Bazel [20]
- CMake [4]: abbrevia Make multipiattaforma e crea file di descrizione successivamente utilizzati da Make
- disfare [12]
- Distributed Make System (DMS) [10] (sembra essere morto)
- dmake [13]
- LSF Fare [15]
- Apache Maven
- mesone
- Costruzione ninja
- NMake [6]: Crea per Microsoft Visual Studio
- PyDoit [8]
- Qmake [11]
- rifare [14]
- SCons [7]
- Waf [9]
La maggior parte di essi è stata progettata pensando alla parallelizzazione e offre un risultato migliore per quanto riguarda il tempo di costruzione rispetto a Make.
Conclusione
Come hai visto, vale la pena pensare alle build parallele in quanto riduce significativamente il tempo di build fino a un certo livello. Tuttavia, non è facile da raggiungere e presenta alcune insidie [3]. Si consiglia di analizzare sia il codice che il relativo percorso di compilazione prima di passare alle build parallele.
Link e riferimenti
- [1] GNU Make Manual: Parallel Execution, https://www.gnu.org/software/make/manual/html_node/Parallel.html
- [2] distcc: https://github.com/distcc/distcc
- [3] John Graham-Cumming: le insidie ei vantaggi della parallelizzazione GNU Make, https://www.cmcrossroad.com/article/insidie-e-benefici-gnu-make-parallelization
- [4] CMake, https://cmake.org/
- [5] LoadTeam, https://www.loadteam.com/
- [6] NMake, https://docs.microsoft.com/en-us/cpp/build/reference/nmake-reference?vista=msvc-160
- [7] SCons, https://www.scons.org/
- [8] PyDoit, https://pydoit.org/
- [9] Waf, https://gitlab.com/ita1024/waf/
- [10] Distributed Make System (DMS), http://www.nongnu.org/dms/indice.html
- [11] Qmake, https://doc.qt.io/qt-5/qmake-manual.html
- [12] distmake, https://sourceforge.net/progetti/distmake/
- [13] dmake, https://docs.oracolo.com/cd/E19422-01/819-3697/dmake.html
- [14] rifai, https://rifai.leggi i documenti.io/it/ultimo/
- [15] LSF Make, http://sunray2.mit.edu/kits/platform-lsf/7.0.6/1/guide/kit_lsf_guide_source/print/lsf_make.PDF
- [16] Aysylu Greenberg: Building a Distributed Build System at Google Scale, GoTo Conference 2016, https://gotocon.com/dl/goto-chicago-2016/slides/AysyluGreenberg_BuildingADistributedBuildSystemAtGoogleScale.PDF
- [17] Debian Build System, rete Autobuilder, https://www.debian.org/devel/buildd/index.it.html
- [18] koji - Sistema di creazione e tracciamento degli RPM, https://pagure.io/koji/
- [19] makefile2graph, https://github.com/lindenb/makefile2graph
- [20] Bazel, https://bazel.costruire/
- [21] Tutorial Makefile, https://makefiletutorial.com/
- [22] Graphviz, http://www.graphviz.organizzazione
- [23] Legge di Amdahl, Wikipedia, https://en.wikipedia.org/wiki/Amdahl%27s_law


