Quando si parla di sistemi distribuiti come sopra, ci imbattiamo nel problema dell'analisi e del monitoraggio. Ogni nodo sta generando molte informazioni sulla propria salute (utilizzo della CPU, memoria, ecc.) E sullo stato dell'applicazione insieme a ciò che gli utenti stanno cercando di fare. Tali dati devono essere registrati in:
- Lo stesso ordine in cui vengono creati,
- Separato in termini di urgenza (analisi in tempo reale o batch di dati) e, soprattutto,,
- Il meccanismo con cui vengono raccolti deve essere esso stesso distribuito e scalabile, altrimenti ci ritroviamo con un unico punto di errore. Qualcosa che il design del sistema distribuito avrebbe dovuto evitare.
Perché usare Kafka?
Apache Kafka viene presentato come una piattaforma di streaming distribuita. Nel gergo di Kafka, Produttori generare continuamente dati (flussi) e Consumatori sono responsabili del trattamento, della conservazione e dell'analisi dello stesso. Kafka Broker sono responsabili di garantire che in uno scenario distribuito i dati possano arrivare dai produttori ai consumatori senza alcuna incoerenza. Un insieme di broker Kafka e un altro software chiamato guardiano dello zoo costituiscono un tipico schieramento di Kafka.
Il flusso di dati da molti produttori deve essere aggregato, partizionato e inviato a più consumatori, c'è un sacco di rimescolamento coinvolto. Evitare l'incoerenza non è un compito facile. Ecco perché abbiamo bisogno di Kafka.
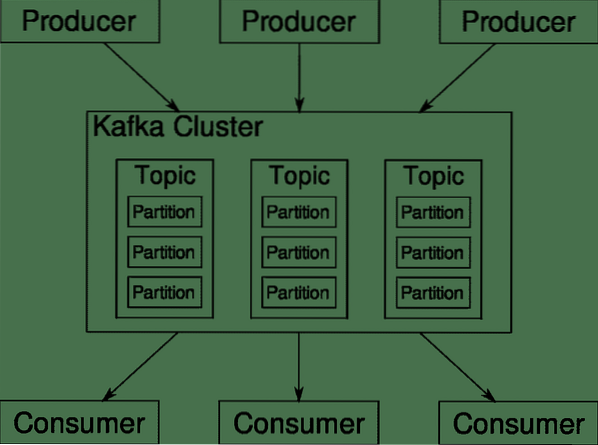
Gli scenari in cui Kafka può essere utilizzato sono piuttosto diversi. Qualsiasi cosa, dai dispositivi IOT al cluster di VM ai tuoi server bare metal on-premise. Ovunque dove molte "cose" richiedono la tua attenzione contemporaneamente.. .Non è molto scientifico, vero?? Bene, l'architettura di Kafka è una tana di coniglio a sé stante e merita un trattamento indipendente. Vediamo prima una distribuzione molto superficiale del software.
Utilizzo di Docker Compose
In qualunque modo fantasioso tu decida di usare Kafka, una cosa è certa: non lo utilizzerai come una singola istanza. Non è pensato per essere utilizzato in questo modo e anche se la tua app distribuita necessita di una sola istanza (broker) per ora, alla fine crescerà e devi assicurarti che Kafka possa tenere il passo.
Docker-compose è il partner perfetto per questo tipo di scalabilità. Invece per eseguire i broker Kafka su diverse VM, lo containerizziamo e sfruttiamo Docker Compose per automatizzare la distribuzione e il ridimensionamento. I contenitori Docker sono altamente scalabili sia su singoli host Docker che su un cluster se utilizziamo Docker Swarm o Kubernetes. Quindi ha senso sfruttarlo per rendere Kafka scalabile.
Iniziamo con una singola istanza di broker. Crea una directory chiamata apache-kafka e al suo interno crea il tuo docker-compose.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim docker-compose.yml
I seguenti contenuti verranno inseriti nel tuo docker-compose.file yml:
versione: '3'Servizi:
guardiano dello zoo:
immagine: wurstmeister/zookeeper
kafka:
immagine: wurstmeister/kafka
porti:
- "9092:9092"
ambiente:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: guardiano dello zoo:2181
Dopo aver salvato i contenuti di cui sopra nel file di composizione, dalla stessa directory eseguire:
$ docker-compose up -dOk, quindi cosa abbiamo fatto qui??
Comprendere il Docker-Compose.yml
Compose avvierà due servizi come elencato nel file yml. Diamo un'occhiata un po' più da vicino al file. La prima immagine è zookeeper che Kafka richiede per tenere traccia dei vari broker, della topologia della rete e della sincronizzazione di altre informazioni. Poiché entrambi i servizi zookeeper e kafka faranno parte della stessa rete bridge (questo viene creato quando eseguiamo docker-compose up ) non è necessario esporre alcuna porta. Il broker di Kafka può parlare con il guardiano dello zoo e questo è tutto ciò di cui ha bisogno la guardia dello zoo zoo.
Il secondo servizio è lo stesso kafka e ne stiamo eseguendo solo una singola istanza, ovvero un broker. Idealmente, vorrai utilizzare più broker per sfruttare l'architettura distribuita di Kafka. Il servizio è in ascolto sulla porta 9092 che è mappata sullo stesso numero di porta sull'host Docker ed è così che il servizio comunica con il mondo esterno.
Il secondo servizio ha anche un paio di variabili d'ambiente. Innanzitutto, KAFKA_ADVERTISED_HOST_NAME è impostato su localhost. Questo è l'indirizzo a cui corre Kafka, e dove possono trovarlo produttori e consumatori. Ancora una volta, questo dovrebbe essere impostato su localhost ma piuttosto sull'indirizzo IP o sul nome host con questo i server possono essere raggiunti nella tua rete. Il secondo è il nome host e il numero di porta del tuo servizio di zookeeper. Dato che abbiamo chiamato il servizio zookeeper... beh, zookeeper questo è il nome dell'host, all'interno della rete docker bridge abbiamo menzionato.
Esecuzione di un semplice flusso di messaggi
Affinché Kafka possa iniziare a lavorare, dobbiamo creare un argomento al suo interno. I client produttori possono quindi pubblicare flussi di dati (messaggi) su detto argomento e i consumatori possono leggere detto flusso di dati, se sono iscritti a quel particolare argomento.
Per fare questo dobbiamo avviare un terminale interattivo con il contenitore Kafka. Elenca i contenitori per recuperare il nome del contenitore kafka. Ad esempio, in questo caso il nostro contenitore si chiama apache-kafka_kafka_1
$ docker psCon il nome del contenitore kafka, ora possiamo cadere all'interno di questo contenitore.
$ docker exec -it apache-kafka_kafka_1 bashbash-4.4#
Apri due terminali così diversi per usarne uno come consumatore e un altro produttore.
Lato produttore
In uno dei prompt (quello che scegli come produttore), inserisci i seguenti comandi:
## Per creare un nuovo argomento chiamato testbash-4.4# kafka-argomenti.sh --create --zookeeper zookeeper:2181 --replication-factor 1
--partizioni 1 --test argomento
## Per avviare un produttore che pubblichi il flusso di dati dallo standard input a kafka
bash-4.4# produttore-console-kafka.sh --broker-list localhost:9092 --topic test
>
Il produttore è ora pronto per ricevere input dalla tastiera e pubblicarlo.
Lato consumatore Consumer
Passa al secondo terminale collegato al tuo contenitore kafka. Il seguente comando avvia un consumatore che si nutre dell'argomento di test:
$ kafka-console-consumatore.sh --bootstrap-server localhost:9092 --topic testTorna al produttore
Ora puoi digitare messaggi nel nuovo prompt e ogni volta che premi Invio la nuova riga viene stampata nel prompt del consumatore consumer. Per esempio:
> Questo è un messaggio.Questo messaggio viene trasmesso al consumatore, tramite Kafka, e puoi vederlo stampato al prompt del consumatore.
Configurazioni del mondo reale
Ora hai un'idea approssimativa di come funziona l'installazione di Kafka. Per il tuo caso d'uso, devi impostare un nome host che non sia localhost, hai bisogno di più di questi broker per far parte del tuo cluster kafka e infine devi configurare i client consumer e producer.
Ecco alcuni link utili:
- Il client Python di Confluent
- Documentazione ufficiale
- Un utile elenco di demo
Spero che tu ti diverta ad esplorare Apache Kafka.


