Sintassi
Grep [schema] [nome file]
Dopo aver usato grep, arriva uno schema. Il modello implica il modo in cui vogliamo usarlo per rimuovere lo spazio extra nei dati. Seguendo il pattern, viene descritto il nome del file attraverso il quale viene eseguito il pattern.
Prerequisito
Per capire facilmente l'utilità di grep, dobbiamo avere Ubuntu installato sul nostro sistema. Fornire i dettagli dell'utente fornendo nome utente e password per avere i privilegi di accesso alle applicazioni di Linux. Dopo aver effettuato l'accesso, apri l'applicazione e cerca un terminale o applica il tasto di scelta rapida di ctrl+alt+T.
Usando [: vuoto:] Parola chiave
Supponiamo di avere un file chiamato bfile con un'estensione di testo. Puoi creare un file sia sull'editor di testo che con una riga di comando nel terminale. Per creare un file sul terminale, inclusi i seguenti comandi.
$ Echo “testo da inserire in un file” > nomefile.TXTNon è necessario creare un file se è già presente. Basta visualizzarlo usando il comando aggiunto:
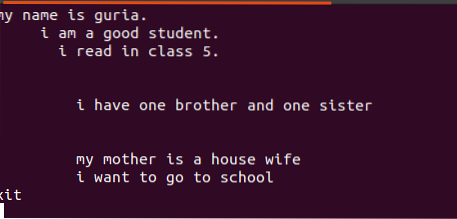
$ echo nomefile.TXTIl testo scritto in questi file contiene spazi tra di loro, come mostrato nella figura sottostante.
![]()
Queste righe vuote possono essere rimosse usando un comando vuoto per ignorare gli spazi vuoti tra le parole o le stringhe.
$ egrep '^[[:blank]]*[^[:blank:]#]' bfile.TXT![]()
Dopo aver applicato la query, gli spazi vuoti tra le righe verranno rimossi e l'output non conterrà più spazio extra. La prima parola viene evidenziata poiché gli spazi tra l'ultima parola della riga e tra le prime parole della riga successiva vengono rimossi. Possiamo anche applicare condizioni sullo stesso comando grep aggiungendo questa funzione vuota per rimuovere lo spazio inutile nell'output.
Usando [: spazio:]
Un altro esempio di ignoranza dello spazio è spiegato qui.
Senza menzionare l'estensione del file, mostreremo prima il file esistente usando il comando.
$ gatto file20![]()
Diamo un'occhiata a come viene rimosso lo spazio extra usando il comando grep oltre alla parola chiave [: space:]. L'opzione -v di Grep aiuterà a stampare righe prive di righe vuote e spaziatura extra inclusa anche in un modulo di paragrafo.
$ grep -v '^[[;spazio:]]*$' file20Vedrai che le linee extra vengono rimosse e l'output è in forma sequenziale per riga. Ecco come la metodologia grep -v è così utile per ottenere l'obiettivo richiesto.
![]()
La menzione delle estensioni di file limita la funzionalità di grep da eseguire solo su particolari estensioni di file, ad esempio.e., .testo o .mp3. Mentre eseguiamo un allineamento su un file di testo, prenderemo fileg.txt come file di esempio. Innanzitutto, mostreremo il testo presente in esso utilizzando la funzione $ cat. L'uscita è la seguente:
![]()
Applicando il comando, è stato ottenuto il nostro file di output. Qui possiamo vedere i dati senza spaziatura tra le righe scritte consecutivamente.
$ grep -v '^[[:space:]]*$' fileg.TXT![]()
Oltre ai comandi lunghi, possiamo anche utilizzare i comandi scritti brevi in Linux e Unix per implementare grep che supporta i caratteri abbreviati in esso.
$ grep '\s' nome file.TXTAbbiamo visto come si ottiene l'output applicando comandi dall'input. Qui impareremo come l'input viene mantenuto dall'output.
$ grep '\S' nomefile.txt > tmp.txt && mv tmp.nome file txt.TXTQui useremo un file di testo temporaneo con estensione di testo denominata tmp.
Usando ^#
Proprio come altri esempi descritti, applicheremo il comando al file di testo usando il comando cat. Possiamo anche visualizzare il testo usando il comando echo.
$ echo nomefile.TXTIl file di testo include 4 righe, con spazio tra di loro. Queste linee spaziali possono essere facilmente rimosse usando un comando particolare.
![]()
Le operazioni estese regolari sono abilitate da -E, che consente tutte le espressioni regolari, in particolare pipe. Un tubo viene utilizzato come condizione "o" opzionale in qualsiasi schema.”^#”. Questo mostra la corrispondenza delle righe di testo nel file che inizia con il segno #. "^$" corrisponderà a tutti gli spazi liberi nel testo o alle righe vuote.
![]()
L'output mostra la completa rimozione dello spazio extra tra le righe presenti nel file di dati. In questo esempio, abbiamo visto che nel comando che "^#" viene prima, il che significa che il testo viene abbinato per primo. “^$” viene dopo | operatore, quindi lo spazio libero viene abbinato in seguito.
Usando ^$
Proprio come l'esempio sopra menzionato, arriveremo con gli stessi risultati perché il comando è quasi lo stesso. Tuttavia, il modello è scritto in modo opposto. File22.txt è un file, che useremo per rimuovere gli spazi.
![]()
Si applica la stessa metodologia tranne il lavoro con priorità. Secondo questo comando, prima verranno abbinati gli spazi liberi, quindi verranno abbinati i file di testo. L'output fornirà una sequenza di linee rimuovendo spazi extra in esse.
![]()
Altri semplici comandi
- Grep '^…' nomefile.
- Grep'.' Nome del file
Entrambi sono così semplici e aiutano a rimuovere gli spazi vuoti nelle righe di testo.
Conclusione
Rimuovere spazi inutili nei file con l'aiuto di espressioni regolari è un approccio abbastanza semplice per ottenere una sequenza uniforme di dati e mantenere la coerenza. Gli esempi sono spiegati in modo dettagliato per migliorare le tue informazioni sull'argomento.


