Gli indici sono tabelle di ricerca specializzate utilizzate dai motori di ricerca delle banche dati per accelerare i risultati delle query. Un indice è un riferimento alle informazioni in una tabella. Ad esempio, se i nomi in una rubrica non sono in ordine alfabetico, dovresti scendere ogni riga e cercare in ogni nome prima di raggiungere il numero di telefono specifico che stai cercando. Un indice velocizza i comandi SELECT e le frasi WHERE, eseguendo l'inserimento dei dati nei comandi UPDATE e INSERT. Indipendentemente dal fatto che gli indici vengano inseriti o cancellati, non vi è alcun impatto sulle informazioni contenute nella tabella. Gli indici possono essere speciali nello stesso modo in cui la limitazione UNIQUE aiuta a evitare record di replica nel campo o insieme di campi per cui esiste l'indice.
Sintassi generale
La seguente sintassi generale viene utilizzata per creare indici.
>> CREATE INDEX nome_indice ON nome_tabella (nome_colonna);Per iniziare a lavorare sugli indici, apri il pgAdmin di Postgresql dalla barra delle applicazioni. Di seguito troverai l'opzione "Server". Fare clic con il tasto destro su questa opzione e collegarla al database.
Come puoi vedere, il database "Test" è elencato nell'opzione "Database". Se non ne hai uno, fai clic con il pulsante destro del mouse su "Database", seleziona l'opzione "Crea" e assegna un nome al database in base alle tue preferenze.
Espandi l'opzione "Schemi" e troverai l'opzione "Tabelle" elencata lì. Se non ne hai uno, fai clic con il pulsante destro del mouse su di esso, vai su "Crea" e fai clic sull'opzione "Tabella" per creare una nuova tabella. Dato che abbiamo già creato la tabella 'emp' puoi vederla nell'elenco.
Prova la query SELECT nell'editor di query per recuperare i record della tabella "emp", come mostrato di seguito.
>> SELEZIONA * DA pubblico.emp ORDINA PER “id” ASC;
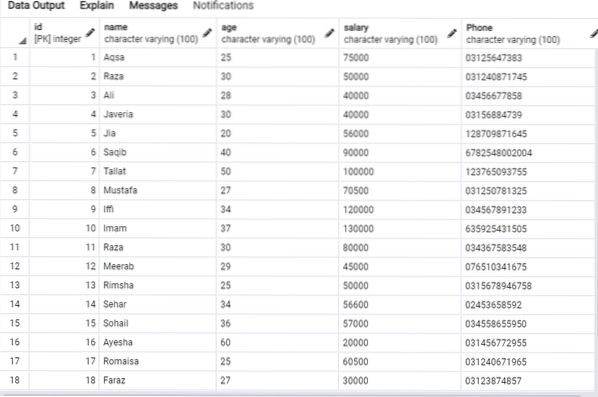
I seguenti dati saranno nella tabella 'emp'.
Crea indici a colonna singola
Espandi la tabella 'emp' per trovare varie categorie, e.g., Colonne, vincoli, indici, ecc. Fai clic con il pulsante destro del mouse su "Indici", vai all'opzione "Crea" e fai clic su "Indice" per creare un nuovo indice.
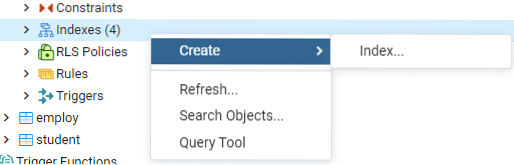
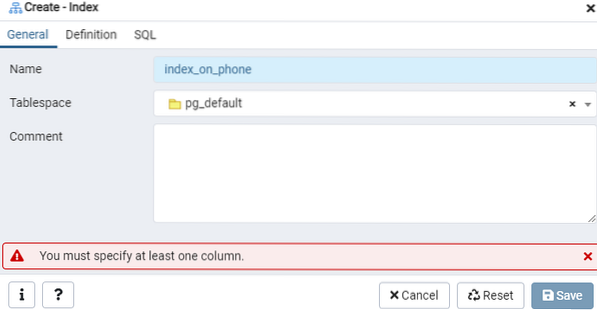
Costruisci un indice per la data tabella 'emp', o eventuale visualizzazione, usando la finestra di dialogo Indice. Qui ci sono due schede: "Generale" e "Definizione".' Nella scheda 'Generale', inserisci un titolo specifico per il nuovo indice nel campo 'Nome'. Scegli il "tablespace" in cui verrà archiviato il nuovo indice utilizzando l'elenco a discesa accanto a "Tablespace".' Come nell'area "Commento", inserisci qui i commenti sull'indice. Per iniziare questo processo, vai alla scheda "Definizione".
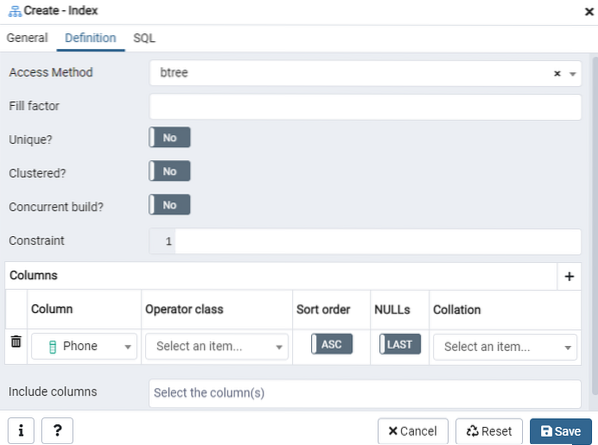
Qui, specifica il "Metodo di accesso" selezionando il tipo di indice. Dopodiché, per creare il tuo indice come "Unico", ci sono molte altre opzioni elencate lì. Nell'area "Colonne", toccare il segno "+" e aggiungere i nomi delle colonne da utilizzare per l'indicizzazione. Come puoi vedere, abbiamo applicato l'indicizzazione solo alla colonna "Telefono". Per iniziare, seleziona la sezione SQL.
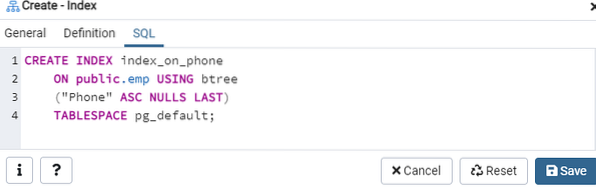
La scheda SQL mostra il comando SQL che è stato creato dai tuoi input durante la finestra di dialogo Indice. Fare clic sul pulsante "Salva" per creare l'indice.
Di nuovo, vai all'opzione "Tabelle" e vai alla tabella "emp". Aggiorna l'opzione "Indici" e troverai l'indice "index_on_phone" appena creato elencato in esso.
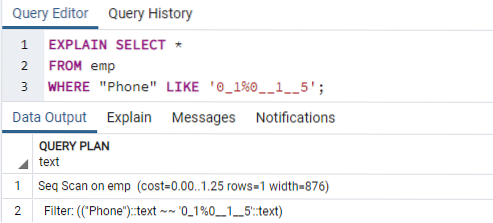
Ora eseguiremo il comando EXPLAIN SELECT per controllare i risultati per gli indici con la clausola WHERE. Ciò si tradurrà nel seguente output, che dice "Seq Scan on emp".' Potresti chiederti perché questo è successo mentre usi gli indici.
Motivo: il pianificatore di Postgres può decidere di non avere un indice per vari motivi. Lo stratega prende le decisioni migliori per la maggior parte del tempo, anche se le ragioni non sono sempre chiare. Va bene se in alcune query viene utilizzata una ricerca per indice, ma non in tutte. Le voci restituite da entrambe le tabelle possono variare, a seconda dei valori fissi restituiti dalla query. Poiché ciò si verifica, una scansione in sequenza è quasi sempre più veloce di una scansione dell'indice, indicando che forse il pianificatore di query aveva ragione nel determinare che il costo dell'esecuzione della query in questo modo è ridotto.
Crea indici di colonne multiple
Per creare indici a più colonne, apri la shell della riga di comando e considera la seguente tabella "studente" per iniziare a lavorare su indici con più colonne.
>> SELEZIONA * DA Studente;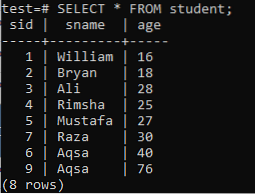
Scrivi la seguente query CREATE INDEX al suo interno. Questa query creerà un indice denominato 'nuovo_indice' nelle colonne 'cognome' e 'età' della tabella 'studente'.
>> CREA INDICE nuovo_indice ON Studente (cognome, età);
Ora elencheremo le proprietà e gli attributi dell'indice 'new_index' appena creato usando il comando '\d'. Come puoi vedere nell'immagine, questo è un indice di tipo btree che è stato applicato alle colonne 'sname' e 'age'.
>> \d nuovo_indice;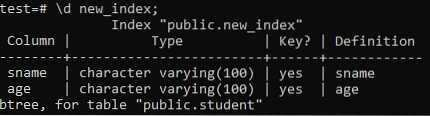
Crea indice UNICO
Per costruire un indice univoco, supponi la seguente tabella 'emp''.
>> SELEZIONA * DA emp;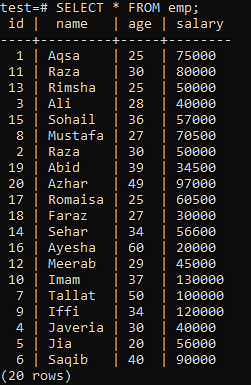
Esegui la query CREATE UNIQUE INDEX nella shell, seguita dal nome dell'indice 'empind' nella colonna 'name' della tabella 'emp'. Nell'output, puoi vedere che l'indice univoco non può essere applicato a una colonna con valori "nome" duplicati.
>> CREA INDICE univoco empind ON emp (nome);
Assicurati di applicare l'indice univoco solo alle colonne che non contengono duplicati. Per la tabella "emp", puoi presumere che solo la colonna "id" contenga valori univoci. Quindi, gli applicheremo un indice univoco.
>> CREA INDICE univoco empind ON emp (id);
Di seguito sono riportati gli attributi dell'indice univoco.
>> \d empid;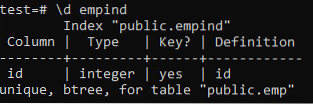
Indice di caduta
L'istruzione DROP viene utilizzata per rimuovere un indice da una tabella.
>> DROP INDEX empind;
Conclusione
Sebbene gli indici siano progettati per migliorare l'efficienza dei database, in alcuni casi non è possibile utilizzare un indice. Quando si utilizza un indice, è necessario considerare le seguenti regole:
- Gli indici non dovrebbero essere scartati per i tavoli piccoli.
- Tabelle con molte operazioni di aggiornamento/aggiornamento batch o aggiunta/inserimento su larga scala.
- Per le colonne con una percentuale sostanziale di valori NULL, gli indici non possono essere confusi-
- vendita.
- L'indicizzazione dovrebbe essere evitata con colonne manipolate regolarmente.


