Conoscere e manipolare i sistemi di gestione dei database ci ha fatto conoscere le alterazioni sui database. Che in genere comporta la creazione, l'inserimento, l'aggiornamento e l'eliminazione di funzioni applicate su tabelle specifiche. In questo articolo vedremo come vengono gestiti i dati con il metodo di inserimento. Dobbiamo creare una tabella in cui vogliamo l'inserimento. L'istruzione di inserimento viene utilizzata per l'aggiunta di nuovi dati nelle righe delle tabelle. L'istruzione Insert di PostgreSQL copre alcune regole per la corretta esecuzione di una query. Per prima cosa dobbiamo menzionare il nome della tabella seguito dai nomi delle colonne (attributi) dove vogliamo inserire le righe. In secondo luogo, dobbiamo inserire i valori, separati da una virgola dopo la clausola VALUE. Infine, ogni valore deve essere nello stesso ordine in cui viene fornita la sequenza di elenchi di attributi durante la creazione di una tabella particolare.
Sintassi
>> INSERIRE IN TABLENAME (colonna1, colonna) VALUES ('value1', 'value2');Qui, una colonna sono gli attributi della tabella. La parola chiave VALUE viene utilizzata per inserire i valori. 'Valore' sono i dati delle tabelle da inserire.
Inserimento di funzioni di riga nella shell PostgreSQL (psql)
Dopo aver installato con successo postgresql, inseriremo il nome del database, il numero di porta e la password. Psql verrà avviato. Quindi eseguiremo query rispettivamente.
Esempio 1: utilizzo di INSERT per aggiungere nuovi record alle tabelle
Seguendo la sintassi, creeremo la seguente query. Per inserire una riga nella tabella, creeremo una tabella denominata "cliente". La rispettiva tabella contiene 3 colonne. Il tipo di dati di particolari colonne dovrebbe essere menzionato per inserire i dati in quella colonna ed evitare la ridondanza. La query per creare una tabella è:

Dopo aver creato la tabella, inseriremo ora i dati inserendo manualmente le righe in query separate. In primo luogo, menzioniamo il nome della colonna per mantenere l'accuratezza dei dati in particolari colonne riguardanti gli attributi. E poi, verranno inseriti i valori. I valori sono codificati da virgole singole, in quanto vanno inseriti senza alcuna alterazione.
>> inserire nel cliente (id, nome, paese) i valori ('1','Alia','Pakistan');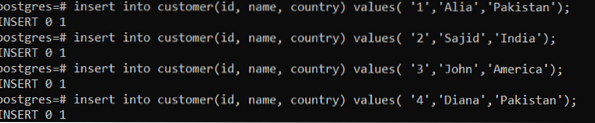
Dopo ogni inserimento riuscito, l'output sarà "0 1", il che significa che viene inserita 1 riga alla volta. Nella query come accennato in precedenza, abbiamo inserito i dati 4 volte. Per visualizzare i risultati, utilizzeremo la seguente query:
>> seleziona * da cliente;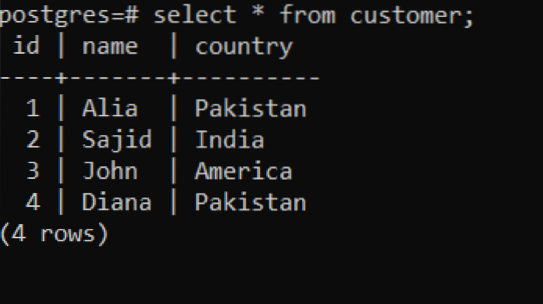
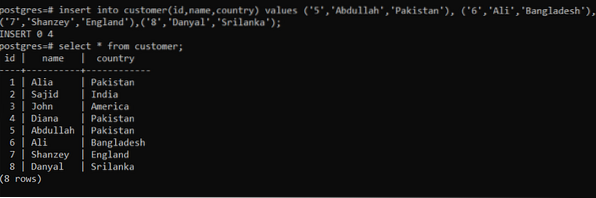
Esempio 2: utilizzo dell'istruzione INSERT nell'aggiunta di più righe in una singola query
Lo stesso approccio viene utilizzato nell'inserimento dei dati ma non nell'introduzione di istruzioni di inserimento molte volte. Inseriremo i dati in una volta utilizzando una determinata query; tutti i valori di una riga sono separati da "Utilizzando la seguente query, otterremo l'output richiesto
Esempio 3: INSERIRE più righe in una tabella in base ai numeri in un'altra tabella
Questo esempio si riferisce all'inserimento di dati da una tabella all'altra. Considera due tabelle, "a" e "b". La tabella "a" ha 2 attributi, i.e., nome e classe. Applicando una query CREATE, introdurremo una tabella. Dopo la creazione della tabella, i dati verranno inseriti utilizzando una query di inserimento.
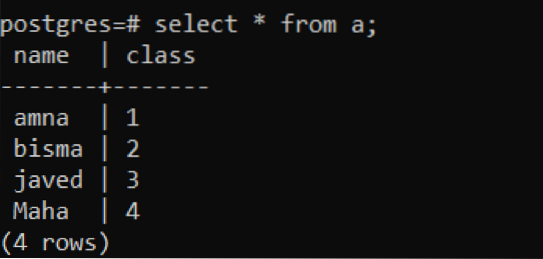
>> Inserire in un valori ('amna', 1), ('bisma','2'), ('javed','3'), ('maha','4');

Quattro valori vengono inseriti nella tabella utilizzando la teoria del superamento. Possiamo verificare utilizzando le istruzioni select.
Allo stesso modo, creeremo la tabella "b", con attributi di tutti i nomi e soggetti. Le stesse 2 query verranno applicate per inserire e recuperare il record dalla tabella corrispondente.
>> crea la tabella b(allnames varchar(30), soggetto varchar(70));
Recupera il record selezionando la teoria.
>> seleziona * da b;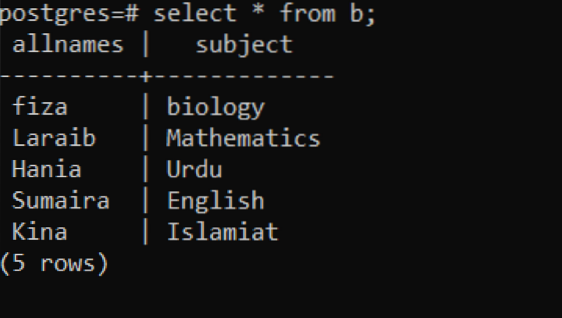
Per inserire i valori della tabella b nella tabella, useremo la seguente query. Questa query funzionerà in modo tale che tutti i nomi nella tabella b verrà inserito nella tabella un con il conteggio dei numeri che mostrano il numero di occorrenze di un determinato numero nella rispettiva colonna della tabella b. “b.allnames" rappresenta la funzione oggetto per specificare la tabella. Conte (b.allnames) funziona per contare l'occorrenza totale. Poiché ogni nome è presente contemporaneamente, la colonna risultante avrà 1 numero.
>> Inserisci in a (nome, classe) seleziona b.tutti i nomi, contare (b.tutti i nomi) dal gruppo b per b.tutti i nomi;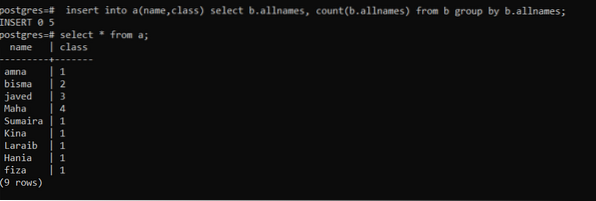
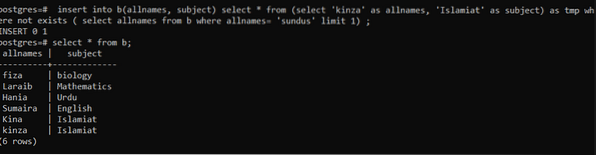
Esempio 4: INSERIRE i dati nelle righe se non esistono
Questa query viene utilizzata per inserire righe se non è presente. Innanzitutto la query fornita controlla se la riga è già presente o meno. Se esiste già, i dati non vengono aggiunti. E se i dati non sono presenti in una riga, il nuovo inserimento verrà mantenuto. Qui tmp è una variabile temporanea utilizzata per memorizzare i dati per un po' di tempo.
Esempio 5: PostgreSQL Upsert utilizzando l'istruzione INSERT
Questa funzione ha due varietà:
- Aggiornamento: se si verifica un conflitto, se il record corrisponde ai dati esistenti nella tabella, viene aggiornato con nuovi dati.
- Se si verifica un conflitto, non fare nulla: Se un record corrisponde ai dati esistenti nella tabella, salta il record o se viene rilevato un errore, viene anche ignorato.
Inizialmente, formeremo una tabella con alcuni dati di esempio.
>> CREATE TABLE tbl2 (ID INT PRIMARY KEY, Name CHARACTER VARYING);Dopo aver creato la tabella inseriremo i dati in tbl2 utilizzando la query:
>> INSERIRE NEI VALORI tbl2 (1,'uzma'), (2,'abdul'), (3,'Hamna'), (4,'fatima'), (5,'shiza'), (6,' javeria');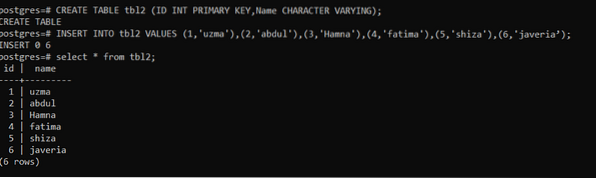
Se si verifica un conflitto, Aggiorna:
>>INSERIRE IN tbl2 VALUES (8,'Rida') IN CONFLITTO (ID) AGGIORNA SET Nome= Escluso.Nome;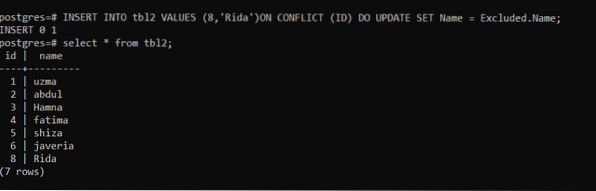
All'inizio, inseriremo i dati utilizzando la query di conflitto di id 8 e il nome Rida. La stessa query verrà utilizzata dopo lo stesso id; il nome sarà cambiato. Ora noterai come verranno cambiati i nomi sullo stesso ID nella tabella.
>> INSERIRE IN tbl2 VALUES (8,'Mahi') IN CONFLITTO (ID) AGGIORNA SET Nome = Escluso.Nome;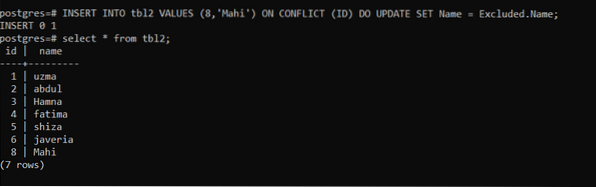
Abbiamo scoperto che c'era un conflitto sull'id "8", quindi la riga specificata viene aggiornata.
Se si verifica un conflitto, non fare nulla
>> INSERIRE NEI VALORI tbl2 (9,'Hira') SUL CONFLITTO (ID) NON FARE NULLA;Usando questa query, viene inserita una nuova riga. Dopodiché, useremo se la stessa query per vedere il conflitto che si è verificato.
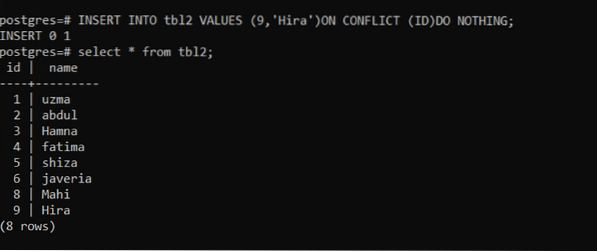
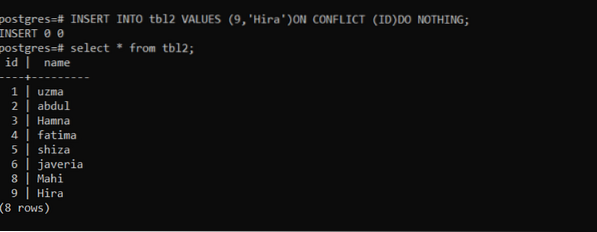
Secondo l'immagine sopra, vedrai che dopo l'esecuzione della query "INSERT 0 0" non viene inserito alcun dato.
Conclusione
Abbiamo dato un'occhiata al concetto di comprensione dell'inserimento di righe nelle tabelle in cui i dati non sono presenti o l'inserimento non viene completato, se viene trovato un record, per ridurre la ridondanza nelle relazioni del database.


