Apache Hadoop è una soluzione per big data per l'archiviazione e l'analisi di grandi quantità di dati. In questo articolo descriveremo in dettaglio i complessi passaggi di configurazione per Apache Hadoop per iniziare con Ubuntu il più rapidamente possibile. In questo post installeremo Apache Hadoop su Ubuntu 17.10 macchine.
Versione Ubuntu
Per questa guida, useremo Ubuntu versione 17 Ubuntu.10 (GNU/Linux 4.13.0-38-generico x86_64).
Aggiornamento dei pacchetti esistenti
Per avviare l'installazione di Hadoop, è necessario aggiornare la nostra macchina con gli ultimi pacchetti software disponibili. Possiamo farlo con:
sudo apt-get update && sudo apt-get -y dist-upgradePoiché Hadoop è basato su Java, dobbiamo installarlo sulla nostra macchina. Possiamo usare qualsiasi versione di Java sopra Java 6. Qui, useremo Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessDownload di file Hadoop
Tutti i pacchetti necessari ora esistono sulla nostra macchina. Siamo pronti per scaricare i file TAR Hadoop richiesti in modo da poter iniziare a configurarli ed eseguire anche un programma di esempio con Hadoop.
In questa guida, installeremo Hadoop v3.0.1. Scarica i file corrispondenti con questo comando:
wget http://mirror.cc.Colombia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.catrame.gzA seconda della velocità della rete, l'operazione può richiedere alcuni minuti poiché il file è di grandi dimensioni:
Download di Hadoop
Trova gli ultimi binari Hadoop qui. Ora che abbiamo scaricato il file TAR, possiamo estrarlo nella directory corrente:
tar xvzf hadoop-3.0.1.catrame.gzQuesto richiederà alcuni secondi per il completamento a causa delle grandi dimensioni del file dell'archivio:
Hadoop annullato dall'archivio
Aggiunto un nuovo gruppo di utenti Hadoop
Poiché Hadoop opera su HDFS, un nuovo file system può distorcere il nostro file system anche sulla macchina Ubuntu. Per evitare questa collisione, creeremo un gruppo utenti completamente separato e lo assegneremo ad Hadoop in modo che contenga i propri permessi. Possiamo aggiungere un nuovo gruppo di utenti con questo comando:
addgroup hadoopVedremo qualcosa come:
Aggiunta di un gruppo di utenti Hadoop
Siamo pronti per aggiungere un nuovo utente a questo gruppo:
useradd -G hadoop hadoopuserTieni presente che tutti i comandi che eseguiamo sono come utente root stesso. Con il comando aove, siamo stati in grado di aggiungere un nuovo utente al gruppo che abbiamo creato.
Per consentire all'utente Hadoop di eseguire operazioni, è necessario fornirgli anche l'accesso root. Apri il /etc/sudoers file con questo comando:
sudo visudoPrima di aggiungere qualsiasi cosa, il file sarà simile a:
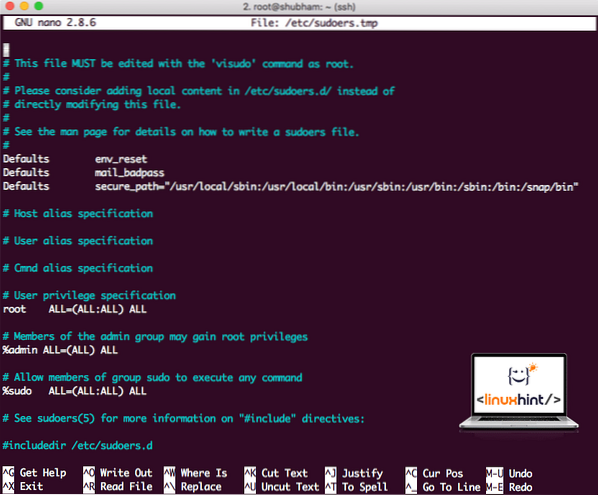
File Sudoers prima di aggiungere qualsiasi cosa
Aggiungi la seguente riga alla fine del file:
hadoopuser ALL=(ALL) ALLOra il file sarà simile a:
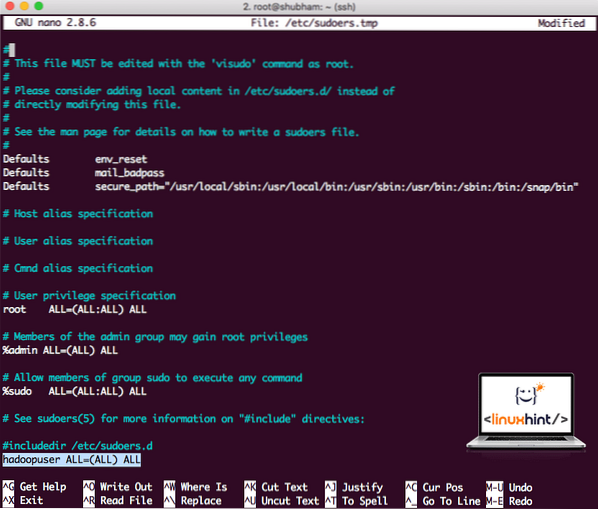
File Sudoers dopo aver aggiunto l'utente Hadoop
Questa era la configurazione principale per fornire ad Hadoop una piattaforma per eseguire azioni. Siamo pronti per configurare un cluster Hadoop a nodo singolo ora.
Configurazione Hadoop a nodo singolo: modalità autonoma
Quando si tratta della vera potenza di Hadoop, di solito è impostato su più server in modo che possa scalare su una grande quantità di set di dati presente in File system distribuito Hadoop (HDFS). Questo di solito va bene con gli ambienti di debug e non viene utilizzato per l'utilizzo in produzione. Per mantenere il processo semplice, spiegheremo come possiamo eseguire una configurazione di un singolo nodo per Hadoop qui.
Una volta completata l'installazione di Hadoop, eseguiremo anche un'applicazione di esempio su Hadoop. A partire da ora, il file Hadoop si chiama hadoop-3.0.1. rinominiamolo in hadoop per un utilizzo più semplice:
mv hadoop-3.0.1 hadoopIl file ora si presenta come:
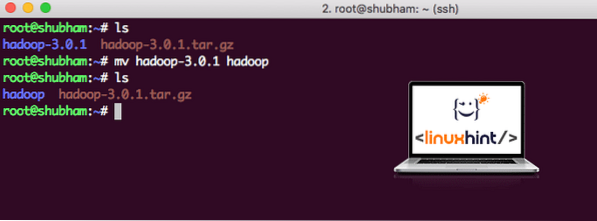
Spostare Hadoop
È ora di utilizzare l'utente hadoop che abbiamo creato in precedenza e assegnare la proprietà di questo file a quell'utente:
chown -R hadoopuser:hadoop /root/hadoopUna posizione migliore per Hadoop sarà la directory /usr/local/, quindi spostiamola lì:
mv hadoop /usr/local/cd /usr/locale/
Aggiunta di Hadoop al percorso
Per eseguire gli script Hadoop, lo aggiungeremo al percorso ora. Per fare ciò, apri il file bashrc:
vi ~/.bashrcAggiungi queste righe alla fine del .bashrc in modo che il percorso possa contenere il percorso del file eseguibile di Hadoop:
# Configura Hadoop e Java Homeesporta HADOOP_HOME=/usr/local/hadoop
esporta JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$HADOOP_HOME/bin
Il file sembra:
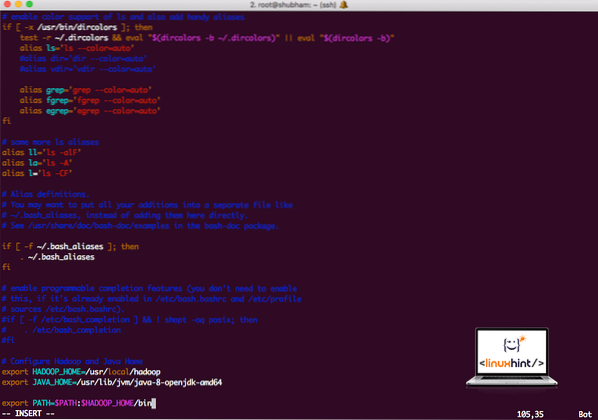
Aggiunta di Hadoop al percorso
Poiché Hadoop utilizza Java, dobbiamo dire al file di ambiente Hadoop hadoop-env.sh Dove si trova. La posizione di questo file può variare in base alle versioni di Hadoop. Per trovare facilmente dove si trova questo file, esegui il seguente comando appena fuori dalla directory Hadoop:
trova hadoop/ -name hadoop-env.shOtterremo l'output per la posizione del file:
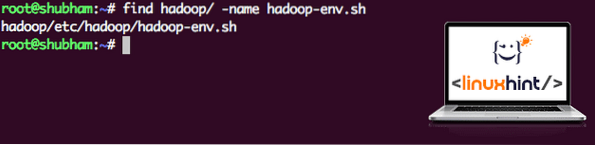
Posizione del file di ambiente
Modifichiamo questo file per informare Hadoop della posizione Java JDK e inseriamo questo nell'ultima riga del file e salviamo:
esporta JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64L'installazione e la configurazione di Hadoop sono ora complete. Siamo pronti per eseguire la nostra applicazione di esempio ora. Ma aspetta, non abbiamo mai fatto un'applicazione di esempio!
Esecuzione di un'applicazione di esempio con Hadoop
In realtà, l'installazione di Hadoop viene fornita con un'applicazione di esempio integrata che è pronta per essere eseguita una volta completata l'installazione di Hadoop. Suona bene, vero?
Eseguire il comando seguente per eseguire l'esempio JAR:
vaso hadoop /root/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.1.jar conteggio parole /root/hadoop/README.txt /root/OutputHadoop mostrerà quanta elaborazione ha fatto sul nodo:
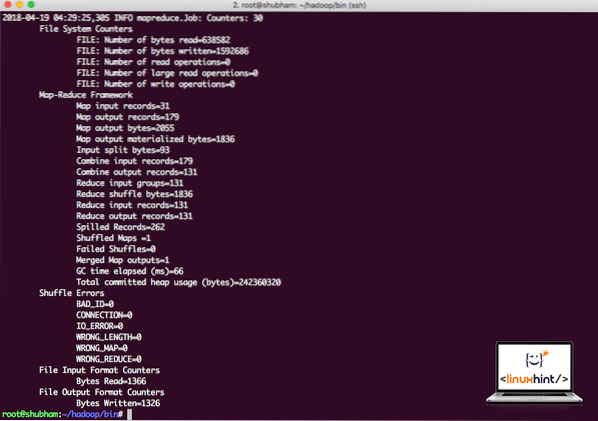
Statistiche di elaborazione Hadoop
Una volta eseguito il seguente comando, vediamo il file part-r-00000 come output. Vai avanti e guarda il contenuto dell'output:
gatto parte-r-00000Otterrai qualcosa come:
Conteggio parole prodotto da Hadoop
Conclusione
In questa lezione, abbiamo esaminato come possiamo installare e iniziare a utilizzare Apache Hadoop su Ubuntu 17.10 macchine. Hadoop è ottimo per archiviare e analizzare grandi quantità di dati e spero che questo articolo ti aiuti a iniziare a usarlo rapidamente su Ubuntu.


