Apache Solr
Apache Solr è uno dei database NoSQL più popolari che può essere utilizzato per archiviare dati e interrogarli quasi in tempo reale. È basato su Apache Lucene ed è scritto in Java. Proprio come Elasticsearch, supporta le query di database tramite API REST. Ciò significa che possiamo utilizzare semplici chiamate HTTP e utilizzare metodi HTTP come GET, POST, PUT, DELETE ecc. per accedere ai dati. Fornisce anche un'opzione per ottenere la forma di XML o JSON tramite le API REST.
In questa lezione studieremo come installare Apache Solr su Ubuntu e inizieremo a lavorarci attraverso un set base di query sul database.
Installazione di Java
Per installare Solr su Ubuntu, dobbiamo prima installare Java. Java potrebbe non essere installato per impostazione predefinita. Possiamo verificarlo usando questo comando:
java -versioneQuando eseguiamo questo comando, otteniamo il seguente output: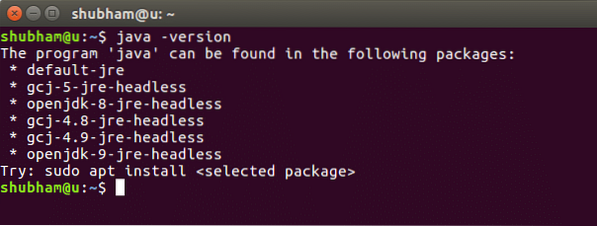
Ora installeremo Java sul nostro sistema. Usa questo comando per farlo:
sudo add-apt-repository ppa:webupd8team/javasudo apt-get update
sudo apt-get install oracle-java8-installer
Una volta che questi comandi sono stati eseguiti, possiamo nuovamente verificare che Java sia installato utilizzando lo stesso comando.
Installazione di Apache Solr
Inizieremo ora con l'installazione di Apache Solr che in realtà è solo una questione di pochi comandi.
Per installare Solr, dobbiamo sapere che Solr non funziona e funziona da solo, anzi, ha bisogno di un contenitore Java Servlet per eseguire, ad esempio, contenitori Jetty o Tomcat Servlet. In questa lezione utilizzeremo il server Tomcat ma l'utilizzo di Jetty è abbastanza simile.
La cosa buona di Ubuntu è che fornisce tre pacchetti con cui Solr può essere facilmente installato e avviato. Sono:
- solr-comune
- solr-tomcat
- solr-molo
È autodescrittivo che solr-common è necessario per entrambi i contenitori mentre solr-jetty è necessario per Jetty e solr-tomcat è necessario solo per il server Tomcat. Poiché abbiamo già installato Java, possiamo scaricare il pacchetto Solr utilizzando questo comando:
sudo wget http://www-eu.apache.org/dist/lucene/solr/7.2.1/sol-7.2.1.cerniera lampoPoiché questo pacchetto include molti pacchetti, incluso il server Tomcat, possono essere necessari alcuni minuti per scaricare e installare tutto. Scarica l'ultima versione dei file Solr da qui.
Una volta completata l'installazione, possiamo decomprimere il file utilizzando il seguente comando:
unzip -q solr-7.2.1.cerniera lampoOra cambia la tua directory nel file zip e vedrai i seguenti file all'interno:
Avvio di Apache Solr Node
Ora che abbiamo scaricato i pacchetti Apache Solr sulla nostra macchina, possiamo fare di più come sviluppatore da un'interfaccia del nodo, quindi avvieremo un'istanza del nodo per Solr dove possiamo effettivamente creare raccolte, archiviare dati ed eseguire query ricercabili.
Eseguire il comando seguente per avviare l'installazione del cluster:
./bin/solr start -e cloudVedremo il seguente output con questo comando: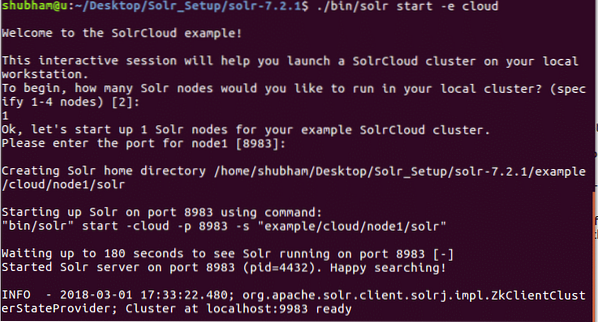
Verranno poste molte domande, ma configureremo un cluster Solr a nodo singolo con tutta la configurazione predefinita. Come mostrato nel passaggio finale, l'interfaccia del nodo Solr sarà disponibile all'indirizzo:
dove 8983 è la porta predefinita per il nodo. Una volta che visitiamo l'URL sopra, vedremo l'interfaccia del nodo: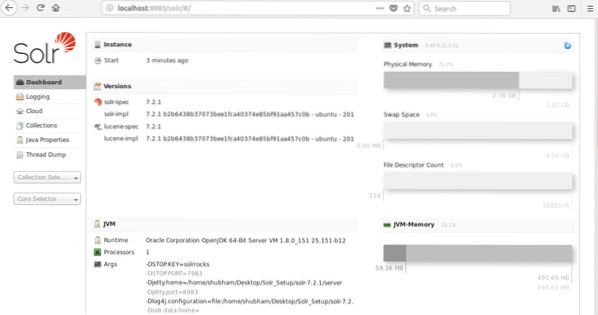
Utilizzo delle raccolte in Solr
Ora che la nostra interfaccia del nodo è attiva e funzionante, possiamo creare una raccolta utilizzando il comando:
./bin/solr create_collection -c linux_hint_collectione vedremo il seguente output:
Evita gli avvertimenti per ora. Ora possiamo persino vedere la raccolta nell'interfaccia del nodo:
Ora possiamo iniziare definendo uno schema in Apache Solr selezionando la sezione schema: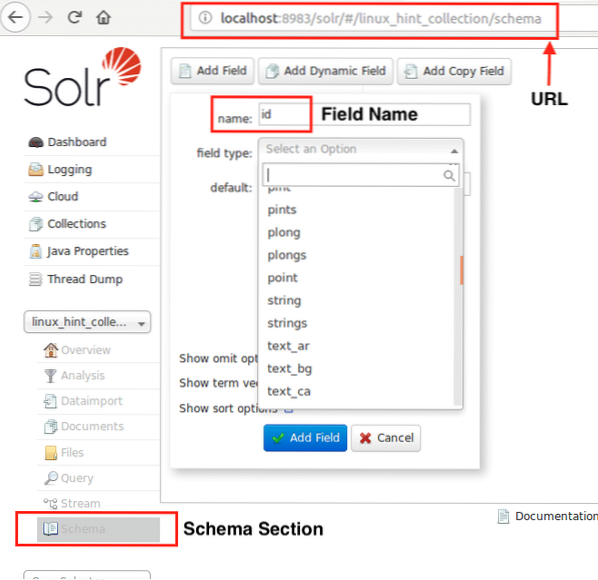
Ora possiamo iniziare a inserire i dati nelle nostre raccolte. Inseriamo un documento JSON nella nostra raccolta qui:
curl -X POST -H 'Tipo di contenuto: application/json''http://localhost:8983/solr/linux_hint_collection/update/json/docs' --data-binary '
"id": "iduye",
"nome": "Shubham"
'
Vedremo una risposta di successo contro questo comando:
Come comando finale, vediamo come possiamo OTTENERE tutti i dati dalla raccolta Solr:
Vedremo il seguente output:


