Apache Spark è uno strumento di analisi dei dati che può essere utilizzato per elaborare i dati da HDFS, S3 o altre origini dati in memoria. In questo post installeremo Apache Spark su Ubuntu 17.10 macchine.
Versione Ubuntu
Per questa guida, useremo Ubuntu versione 17 Ubuntu.10 (GNU/Linux 4.13.0-38-generico x86_64).
Apache Spark fa parte dell'ecosistema Hadoop per i Big Data. Prova a installare Apache Hadoop e crea un'applicazione di esempio con esso.
Aggiornamento dei pacchetti esistenti
Per avviare l'installazione di Spark, è necessario aggiornare la nostra macchina con gli ultimi pacchetti software disponibili. Possiamo farlo con:
sudo apt-get update && sudo apt-get -y dist-upgradePoiché Spark è basato su Java, dobbiamo installarlo sulla nostra macchina. Possiamo usare qualsiasi versione di Java sopra Java 6. Qui, useremo Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessDownload di file Spark
Tutti i pacchetti necessari ora esistono sulla nostra macchina. Siamo pronti per scaricare i file TAR Spark richiesti in modo che possiamo iniziare a configurarli ed eseguire un programma di esempio anche con Spark.
In questa guida, installeremo Scintilla v2.3.0 disponibile qui:
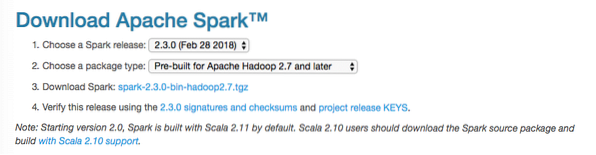
Pagina di download di Spark
Scarica i file corrispondenti con questo comando:
wget http://www-us.apache.org/dist/spark/spark-2.3.0/scintilla-2.3.0-bin-hadoop2.7.tgzA seconda della velocità della rete, l'operazione può richiedere alcuni minuti poiché il file è di grandi dimensioni:
Download di Apache Spark
Ora che abbiamo scaricato il file TAR, possiamo estrarlo nella directory corrente:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgzQuesto richiederà alcuni secondi per il completamento a causa delle grandi dimensioni del file dell'archivio:
File non archiviati in Spark
Quando si tratta di aggiornare Apache Spark in futuro, può creare problemi a causa degli aggiornamenti del percorso. Questi problemi possono essere evitati creando un softlink a Spark. Esegui questo comando per creare un collegamento software:
ln -s scintilla-2.3.0-bin-hadoop2.7 scintilleAggiunta di Spark al percorso
Per eseguire gli script Spark, lo aggiungeremo al percorso ora. Per fare ciò, apri il file bashrc:
vi ~/.bashrcAggiungi queste righe alla fine del .bashrc in modo che il percorso possa contenere il percorso del file eseguibile Spark:
SPARK_HOME=/LinuxHint/sparkexport PATH=$SPARK_HOME/bin:$PATH
Ora, il file si presenta come:
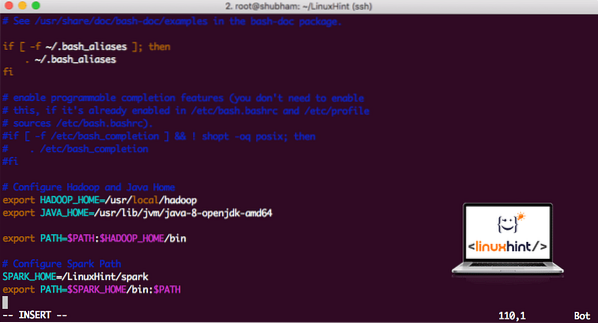
Aggiungere Spark a PATH
Per attivare queste modifiche, esegui il seguente comando per il file bashrc:
fonte ~/.bashrcAvvio di Spark Shell
Ora, quando siamo appena fuori dalla directory spark, esegui il seguente comando per aprire apark shell:
./spark/bin/spark-shellVedremo che la shell Spark è aperta ora:
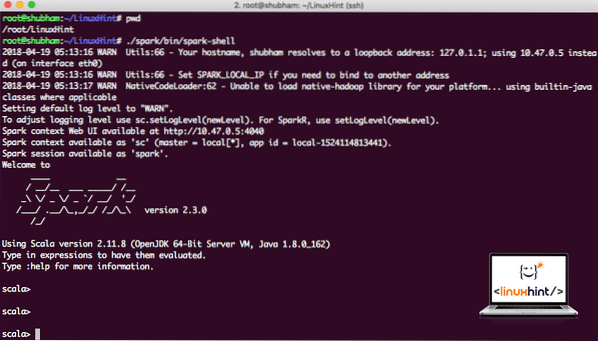
Avvio di Spark shell
Possiamo vedere nella console che Spark ha aperto anche una Web Console sulla porta 404. Facciamo una visita:
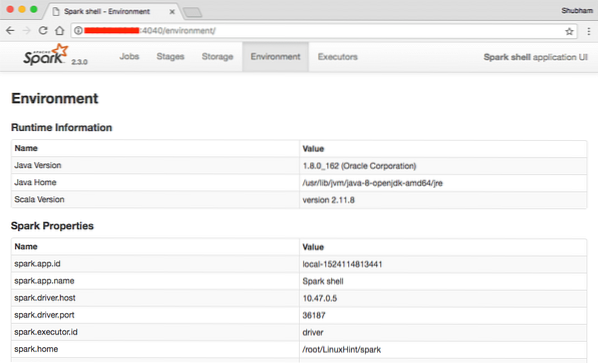
Console Web Apache Spark
Anche se opereremo sulla console stessa, l'ambiente web è un posto importante da considerare quando esegui lavori Spark pesanti in modo da sapere cosa sta succedendo in ogni lavoro Spark che esegui.
Controlla la versione della shell Spark con un semplice comando:
sc.versioneRestituiremo qualcosa come:
res0: Stringa = 2.3.0Creare un'applicazione Spark di esempio con Scala
Ora creeremo un esempio di applicazione Word Counter con Apache Spark. Per fare ciò, carica prima un file di testo in Spark Context sulla shell Spark:
scala> var Data = sc.textFile("/root/LinuxHint/spark/README.md")Dati: organizzazione.apache.scintilla.rdd.RDD[Stringa] = /root/LinuxHint/spark/README.md MapPartitionsRDD[1] at textFile at :24
scala>
Ora, il testo presente nel file deve essere suddiviso in token che Spark può gestire:
scala> var token = Dati.flatMap(s => s.Diviso(" "))token: org.apache.scintilla.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at :25
scala>
Ora, inizializza il conteggio per ogni parola su 1:
scala> var token_1 = token.mappa(e => (s,1))tokens_1: org.apache.scintilla.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] sulla mappa a :25
scala>
Infine, calcola la frequenza di ogni parola del file:
var sum_each = token_1.reduceByKey((a, b) => a + b)È ora di guardare l'output del programma. Raccogli i gettoni e i rispettivi conteggi:
scala> sum_ogni.raccogliere()res1: Array[(String, Int)] = Array((package,1), (For,3), (Programs,1), (processing.,1), (Perché,1), (Il,1), (pagina](http://spark.apache.organizzazione/documentazione.html).,1), (cluster.,1), (its,1), ([run,1), (than,1), (APIs,1), (have,1), (try,1), (computation,1), (through,1 ), (diversi,1), (Questo,2), (grafico,1), (Alveare,2), (stoccaggio,1), (["Specificando,1), (To,2), ("filato" ,1), (Once,1), (["Utile,1), (prefer,1), (SparkPi,2), (engine,1), (version,1), (file,1), (documentation ,,1), (elaborazione,,1), (il,24), (sono,1), (sistemi.,1), (params,1), (not,1), (different,1), (refer,2), (Interactive,2), (R,,1), (dato.,1), (if,4), (build,4), (quando,1), (be,2), (Tests,1), (Apache,1), (thread,1), (programs,,1 ), (compreso, 4), (./bin/run-example,2), (Spark.,1), (pacchetto.,1), (1000).count(),1), (Versioni,1), (HDFS,1), (D…
scala>
Eccellente! Siamo stati in grado di eseguire un semplice esempio di Word Counter utilizzando il linguaggio di programmazione Scala con un file di testo già presente nel sistema.
Conclusione
In questa lezione, abbiamo esaminato come possiamo installare e iniziare a utilizzare Apache Spark su Ubuntu 17.10 macchina ed eseguire anche un'applicazione di esempio su di essa.
Leggi altri post basati su Ubuntu qui.


