dd caratteristiche
"dd" può essere utilizzato per vari scopi:
- Utilizzando “dd” è possibile leggere e/o scrivere direttamente da/su file diversi purché la funzione sia già implementata nei rispettivi driver.
- È super utile per scopi come il backup del settore di avvio, l'ottenimento di dati casuali, ecc.
- Conversione dei dati, ad esempio, conversione da ASCII a codifica EBCDIC.
utilizzo dd
Ecco alcuni degli usi più comuni e interessanti di "dd". Certo, "dd" è molto più capace di queste cose. Se sei interessato, consiglio sempre di consultare altre risorse approfondite su “dd”.
Posizione
quale dd
Come indica l'output, ogni volta che viene eseguito "dd", viene avviato da "/usr/bin/dd".
Utilizzo di base
Ecco la struttura che segue "dd".
dd se=Ad esempio, creiamo un file con dati casuali. Ci sono alcuni file speciali incorporati in Linux che appaiono come file normali come "/dev/zero" che produce un flusso continuo di NULL, "/dev/random" che produce dati casuali continui.
dd if=/dev/urandom of=~/Desktop/random.txt bs=1M conteggio=5
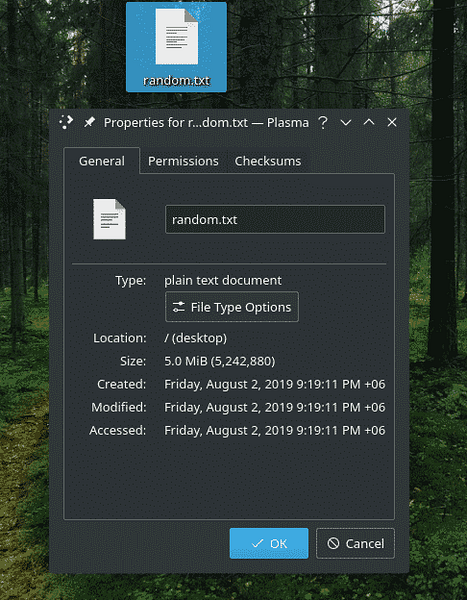
Le primissime opzioni sono autoesplicative. Significa usare "/dev/urandom" come fonte di dati e "~/Desktop/random".txt" come destinazione. Quali sono le altre opzioni??
Qui, "bs" sta per "dimensione del blocco". Quando dd sta scrivendo dati, scrive in blocchi. Usando questa opzione, la dimensione del blocco può essere definita. In questo caso, il valore "1M" dice che la dimensione del blocco è 1 megabyte.
“count” decide il numero di blocchi da scrivere. Se non risolto, "dd" continuerà il processo di scrittura a meno che il flusso di input non termini. In questo caso, "/dev/urandom" continuerà a generare dati all'infinito, quindi questa opzione era fondamentale in questo esempio.
Backup dei dati
Usando questo metodo, "dd" può essere usato per scaricare i dati di un'intera unità! Tutto ciò che serve è indicare l'unità come fonte.
dd se=
Se stai per intraprendere tali azioni, assicurati che la tua fonte non sia una directory. "dd" non ha idea di come elaborare una directory, quindi le cose non funzioneranno.

"dd" sa solo come lavorare con i file. Quindi, se hai bisogno di eseguire il backup di una directory, usa prima tar per archiviarla, quindi usa "dd" per trasferirla su un file.
tar cvJf demo.catrame.xz Dir Demo/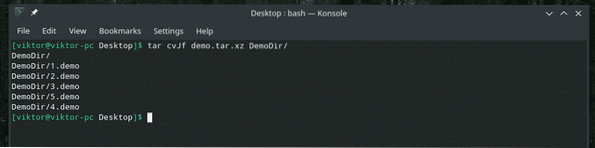

Nel prossimo esempio, eseguiremo un'operazione molto delicata: eseguire il backup dell'MBR! Ora, se il tuo sistema utilizza MBR (Master Boot Record), allora si trova nei primi 512 byte del disco di sistema: 466 byte per il bootloader, altri per la tabella delle partizioni.
Esegui questo comando per eseguire il backup del record MBR.
dd if=/dev/sda of=~/Desktop/mbr.img bs=512 conteggio=1
Ripristino dati
Per qualsiasi backup, è necessario il modo di ripristinare i dati. Nel caso di "dd", il processo di ripristino è leggermente diverso da qualsiasi altro strumento. Devi riscrivere il file di backup su una cartella/partizione/dispositivo simile.
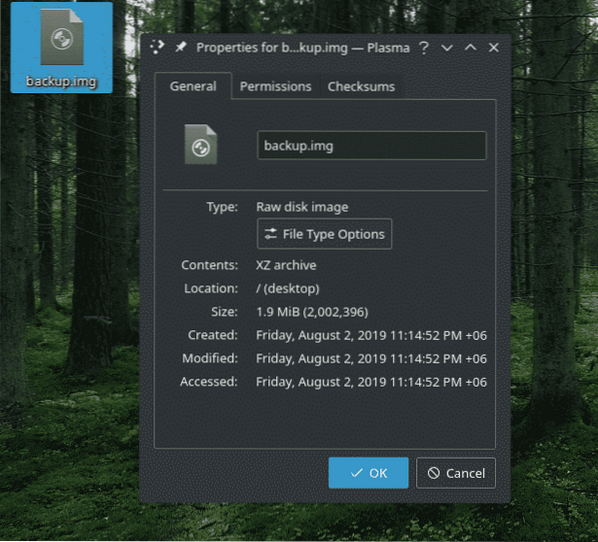
Ad esempio, ho questo "backup.img” contenente il “demo.catrame.xz" file. Per estrarlo, ho usato il seguente comando.
dd if=backup.img of=demo.catrame.xz
Ancora una volta, assicurati di scrivere l'output in un file. "dd" non va bene con le directory, ricorda?
Allo stesso modo, se "dd" è stato utilizzato per creare un backup di una partizione, il ripristino richiederebbe il seguente comando.
dd se=
Ad esempio, che ne dici di ripristinare l'MBR di cui abbiamo eseguito il backup in precedenza??
dd if=mbr.img of=/dev/sda
Opzioni “dd”
Ad un certo punto in questa guida, hai affrontato alcune opzioni "dd" come "bs" e "count", giusto? Beh, ce ne sono di più. Ecco una breve lista di cosa sono e come usarli.
- obs: determina la dimensione dei dati da scrivere alla volta. Il valore predefinito è 512 byte.

- cbs: determina la dimensione dei dati da convertire alla volta.

- ibs: determina la dimensione dei dati da leggere alla volta.
- conteggio: copia solo N blocchi

- ricerca: Salta N blocchi all'inizio dell'output

- skip: Salta N blocchi all'inizio dell'input







Opzioni aggiuntive:
- nocreat: non creare il file di output
- notruc: non troncare il file di output
- noerror: continua l'operazione, anche dopo aver riscontrato un errore
- fdatasync: scrive i dati nella memoria fisica prima che il processo termini
- fsync: simile a fdatasync, ma scrive anche i metadati
- iflag: modifica l'operazione in base a vari flag. I flag disponibili includono: aggiungi a Aggiungi dati all'output

Opzioni aggiuntive:
- directory: affrontare una directory fallirà l'operazione
- dsync: I/O sincronizzato per i dati
- sync: simile a dsync ma include metadati
- nocache: richieste di eliminazione della cache.
- nofollow: non seguire alcun collegamento simbolico

Opzioni aggiuntive:
- count_bytes: simile a "count=N"
- search_bytes: simile a "seek=N"
- skip_bytes: simile a "skip=N"
Come hai visto, è possibile impilare più flag e opzioni in un singolo comando "dd" per modificare il comportamento dell'operazione.
dd if=demo.txt di=demo1.txt bs=10 conteggio=100 conv=ebcdiciflag=append,nocache,nofollow,sync

Pensieri finali
Il flusso di lavoro di "dd" è piuttosto semplice. Tuttavia, perché "dd" brilli davvero, dipende da te. Ci sono un sacco di modi creativi in cui "dd" può essere usato per eseguire interazioni intelligenti.
Per approfondimenti su “dd” e tutte le sue opzioni, consulta la pagina man e info.
uomo dd

