Per comprendere il concetto di ricerca full-text, devi ricordare la conoscenza della ricerca di pattern tramite la parola chiave LIKE. Quindi, supponiamo una tabella 'person' nel database 'test' con i seguenti record al suo interno.
>> SELEZIONA * DA persona;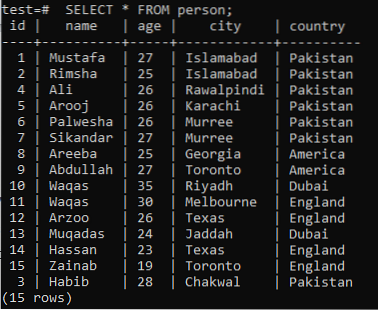
Supponiamo che tu voglia recuperare i record di questa tabella, dove il "nome" della colonna ha un carattere "i" in uno qualsiasi dei suoi valori. Prova la seguente query SELECT mentre usi la clausola LIKE nella shell dei comandi. Dall'output di seguito, puoi vedere che abbiamo solo 5 record per questo particolare personaggio 'i' nella colonna 'nome'.
>> SELECT * FROM persona WHERE nome LIKE '%i%';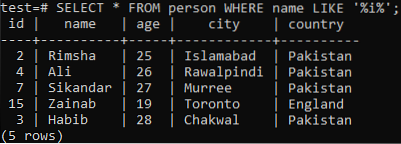
Utilizzo del settore televisivo:
A volte è inutile usare la parola chiave LIKE per fare una rapida ricerca di pattern, anche se la parola è lì. Forse prenderesti in considerazione l'utilizzo di espressioni standard e, sebbene questa sia un'alternativa fattibile, le espressioni regolari sono sia forti che lente. Avere un vettore procedurale per intere parole in un testo, una descrizione vernacolare di quelle parole, è un modo molto più efficiente per affrontare questo problema. Il concetto di ricerca testuale completa e il tipo di dati tsvector è stato creato per rispondere ad esso. Ci sono due metodi in PostgreSQL che fanno proprio quello che vogliamo:
- To_tvsector: Utilizzato per creare un elenco di token (ts significa "ricerca testuale").
- To_tsquery: Utilizzato per cercare nel vettore l'incidenza di termini o frasi specifici.
Esempio 01:
Iniziamo con una semplice illustrazione della creazione di un vettore. Supponiamo di voler creare un vettore per la stringa: "Alcune persone hanno i capelli castani ricci attraverso un'adeguata spazzolatura.". Quindi devi scrivere una funzione to_tvsector() insieme a questa frase tra parentesi di una query SELECT come allegato di seguito. Dall'output seguente, puoi vedere che produrrebbe un vettore di riferimenti (posizioni di file) per ciascun token e anche dove i termini con poco contesto, come articoli (the) e congiunzioni (e, o), vengono deliberatamente ignorati.
>> SELECT to_tsvector('Alcune persone hanno i capelli castani ricci se spazzolati adeguatamente');
Esempio 02:
Supponiamo di avere due documenti con alcuni dati in entrambi. Per memorizzare questi dati, ora utilizzeremo un esempio reale di generazione di token. Supponiamo di aver creato una tabella "Dati" nel "test" del database con alcune colonne utilizzando la query CREATE TABLE di seguito. Non dimenticare di creare una colonna di tipo TVSECTOR denominata "token" al suo interno. Dall'output qui sotto, puoi dare un'occhiata alla tabella che è stata creata.
>> CREATE TABLE Data (Id SERIAL PRIMARY KEY, info TEXT, token TSVECTOR);
Ora tocca a noi aggiungere i dati complessivi di entrambi i documenti in questa tabella. Quindi prova il comando INSERT di seguito nella shell della riga di comando per farlo. Infine, i record di entrambi i documenti sono stati aggiunti con successo nella tabella "Dati".
>> INSERT INTO Data (info) VALUES ('Due torti non possono mai farne uno giusto.'), ('Lui è quello che può giocare a calcio.'), ('Posso avere un ruolo in questo??'), ('Il dolore che si ha dentro non si può capire'), ('Porta pesca nella tua vita);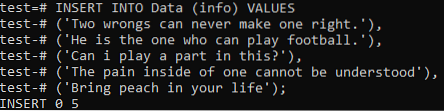
Ora devi colonizzare la colonna token di entrambi i documenti con il loro vettore specifico. Alla fine, una semplice query UPDATE riempirà la colonna dei token con il loro vettore corrispondente per ogni file. Quindi, per farlo, devi eseguire la query indicata di seguito nella shell dei comandi. L'output mostra che l'aggiornamento è stato finalmente effettuato.
>> AGGIORNA dati f1 SET token = to_tsvector(f1.info) DA Dati f2;
Ora che abbiamo tutto a posto torniamo alla nostra illustrazione di "si può" con una scansione. To_tsquery con l'operatore AND, come detto in precedenza, non fa differenza tra le posizioni dei file nei file come mostrato dall'output indicato di seguito.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('can & one');
Esempio 04:
Per trovare parole che sono "accanto a" l'un l'altro, proveremo la stessa query con il '<->'operatore. La modifica viene visualizzata nell'output di seguito.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('can <-> uno');
Ecco un esempio di nessuna parola immediata accanto a un'altra.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('one <-> dolore');
Esempio 05:
Troveremo le parole che non sono immediatamente una accanto all'altra usando un numero nell'operatore distanza per fare riferimento alla distanza. La vicinanza tra "portare" e "vita" è di 4 parole a parte dall'immagine visualizzata.
>> SELECT * FROM dati WHERE token @@ to_tsquery('portare <4> vita');
Per verificare la vicinanza tra le parole per quasi 5 parole è allegato di seguito.
>> SELECT * FROM dati WHERE token @@ to_tsquery('sbagliato <5> giusto');
Conclusione:
Infine, hai eseguito tutti gli esempi semplici e complicati di ricerca full-text utilizzando gli operatori e le funzioni To_tvsector e to_tsquery.


