Individuare e selezionare gli elementi dalla pagina web è la chiave per il web scraping con Selenium. Per localizzare e selezionare elementi dalla pagina web, puoi usare i selettori XPath in Selenium.
In questo articolo, ti mostrerò come individuare e selezionare elementi dalle pagine Web utilizzando i selettori XPath in Selenium con la libreria Python Selenium. Quindi iniziamo.
Prerequisiti:
Per provare i comandi e gli esempi di questo articolo, devi avere,
- Una distribuzione Linux (preferibilmente Ubuntu) installata sul tuo computer.
- Python 3 installato sul tuo computer.
- PIP 3 installato sul tuo computer.
- Pitone virtualenv pacchetto installato sul tuo computer.
- Browser web Mozilla Firefox o Google Chrome installati sul tuo computer.
- Deve sapere come installare Firefox Gecko Driver o Chrome Web Driver.
Per soddisfare i requisiti 4, 5 e 6, leggi il mio articolo Introduzione al selenio in Python 3. Puoi trovare molti articoli sugli altri argomenti su LinuxHint.come. Assicurati di controllarli se hai bisogno di assistenza.
Configurazione di una directory di progetto:
Per mantenere tutto organizzato, crea una nuova directory di progetto selenio-xpath/ come segue:
$ mkdir -pv selenium-xpath/drivers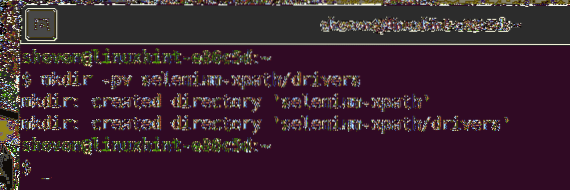
Vai a selenio-xpath/ directory del progetto come segue:
$ cd selenio-xpath/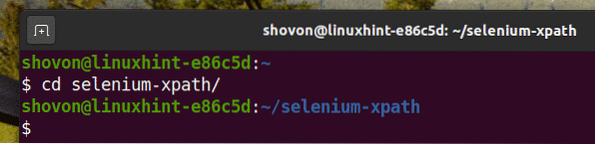
Crea un ambiente virtuale Python nella directory del progetto come segue:
$ virtualenv .venv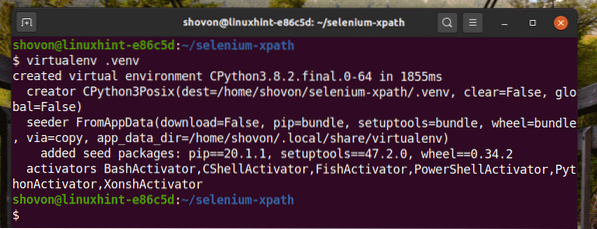
Attiva l'ambiente virtuale come segue:
$ fonte .venv/bin/activate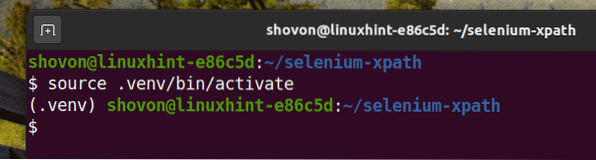
Installa la libreria Selenium Python usando PIP3 come segue:
$ pip3 installa selenio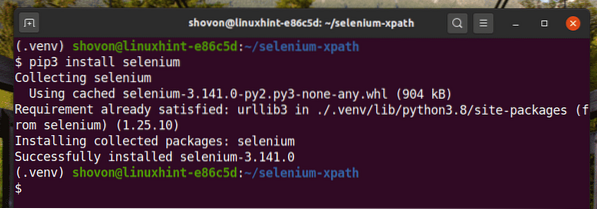
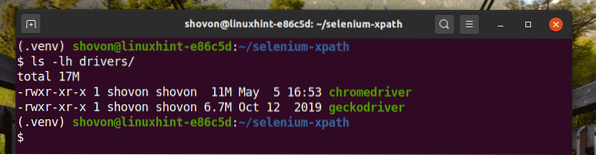
Scarica e installa tutti i driver web necessari nel autisti/ directory del progetto. Ho spiegato il processo di download e installazione dei driver web nel mio articolo Introduzione al selenio in Python 3.
Ottieni il selettore XPath utilizzando Chrome Developer Tool:
In questa sezione, ti mostrerò come trovare il selettore XPath dell'elemento della pagina web che desideri selezionare con Selenium utilizzando lo strumento di sviluppo integrato del browser web Google Chrome.
Per ottenere il selettore XPath utilizzando il browser web Google Chrome, apri Google Chrome e visita il sito web da cui desideri estrarre i dati. Quindi, premere il tasto destro del mouse (RMB) su un'area vuota della pagina e fare clic su Ispezionare per aprire il Strumento per sviluppatori Chrome.
Puoi anche premere
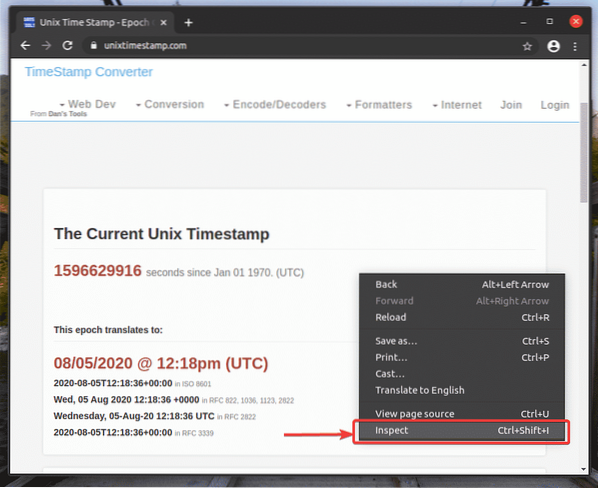
Strumento per sviluppatori Chrome dovrebbe essere aperto.
Per trovare la rappresentazione HTML dell'elemento della pagina Web desiderato, fare clic su Ispezionare(
), come indicato nello screenshot qui sotto.
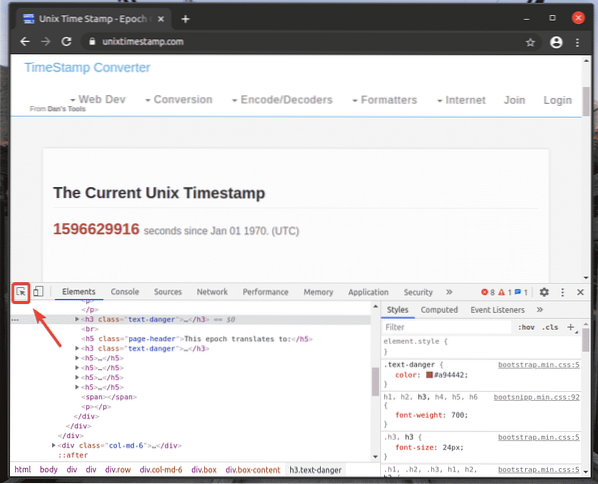
Quindi, passa il mouse sull'elemento della pagina Web desiderato e premi il pulsante sinistro del mouse (LMB) per selezionarlo.
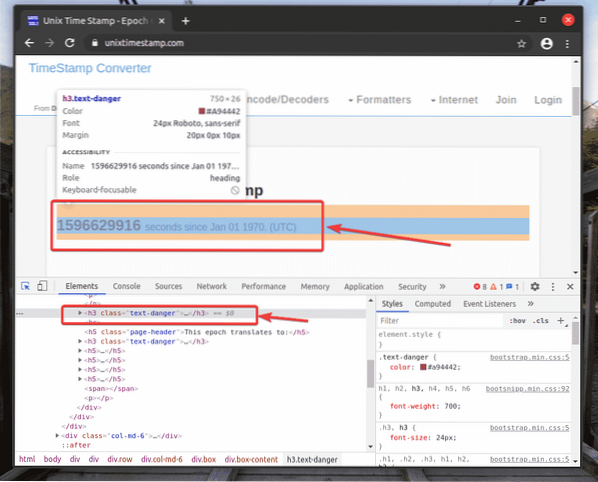
La rappresentazione HTML dell'elemento web che hai selezionato sarà evidenziata nel Elementi scheda del Strumento per sviluppatori Chrome, come puoi vedere nello screenshot qui sotto.
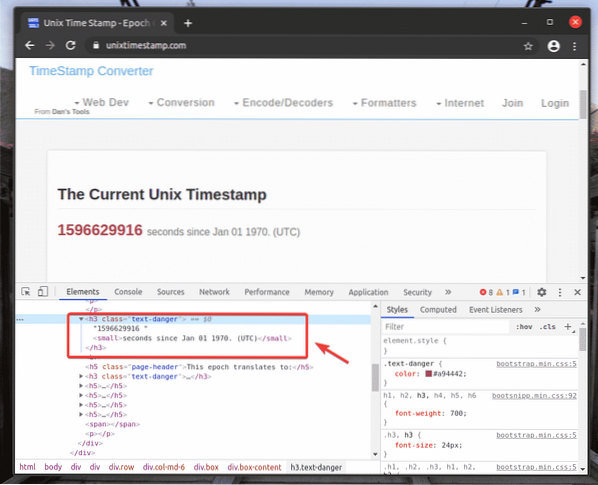
Per ottenere il selettore XPath dell'elemento desiderato, seleziona l'elemento dal Elementi scheda di Strumento per sviluppatori Chrome e fai clic con il pulsante destro del mouse (RMB) su di esso. Quindi, seleziona copia > Copia XPath, come indicato nello screenshot qui sotto.
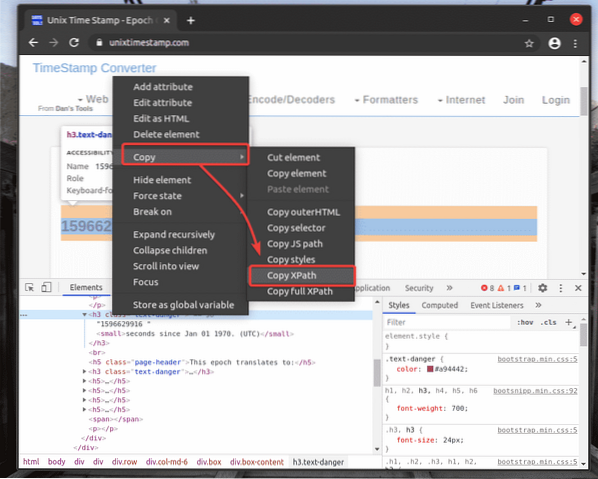
Ho incollato il selettore XPath in un editor di testo. Il selettore XPath appare come mostrato nello screenshot qui sotto.

Ottieni il selettore XPath utilizzando Firefox Developer Tool:
In questa sezione, ti mostrerò come trovare il selettore XPath dell'elemento della pagina Web che desideri selezionare con Selenium utilizzando lo strumento di sviluppo integrato nel browser Web Mozilla Firefox.
Per ottenere il selettore XPath utilizzando il browser Web Firefox, aprire Firefox e visitare il sito Web da cui si desidera estrarre i dati. Quindi, premere il tasto destro del mouse (RMB) su un'area vuota della pagina e fare clic su Ispeziona elemento (Q) per aprire il Strumento per sviluppatori Firefox.
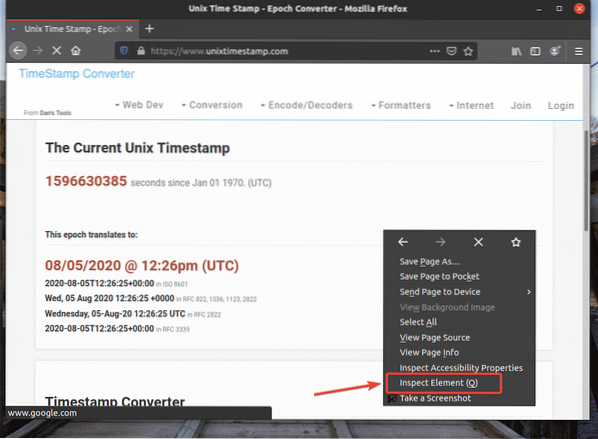
Strumento per sviluppatori Firefox dovrebbe essere aperto.
Per trovare la rappresentazione HTML dell'elemento della pagina Web desiderato, fare clic su Ispezionare(
), come indicato nello screenshot qui sotto.
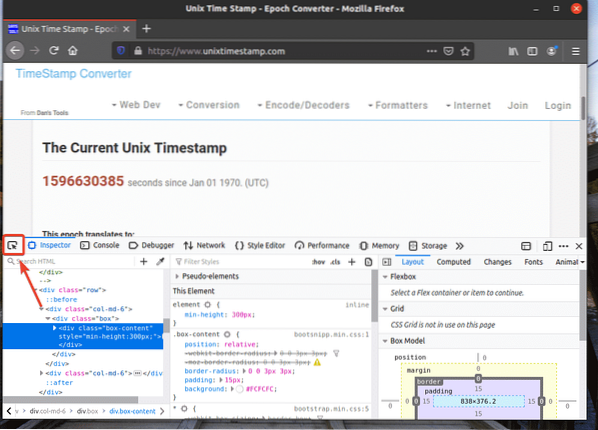
Quindi, passa il mouse sull'elemento della pagina Web desiderato e premi il pulsante sinistro del mouse (LMB) per selezionarlo.
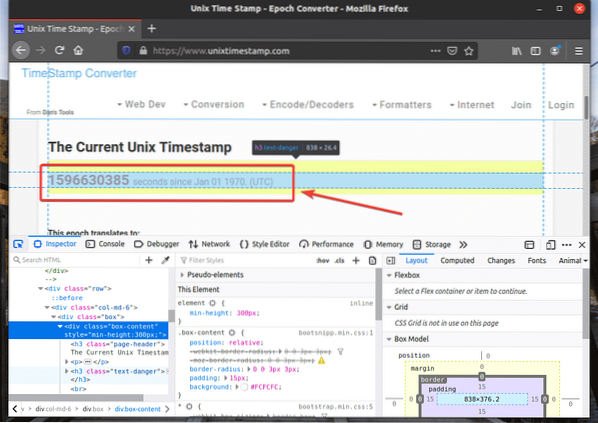
La rappresentazione HTML dell'elemento web che hai selezionato sarà evidenziata nel Ispettore scheda di Strumento per sviluppatori Firefox, come puoi vedere nello screenshot qui sotto.
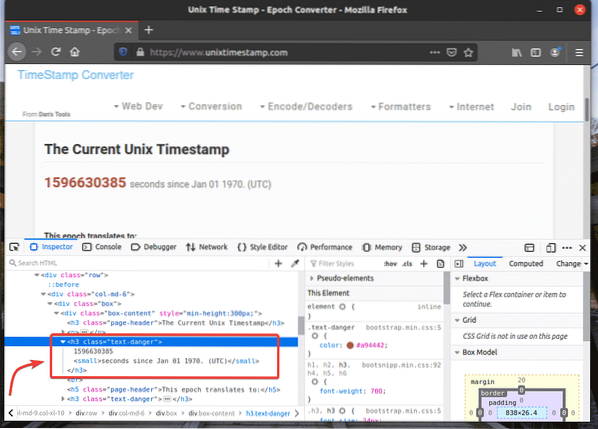
Per ottenere il selettore XPath dell'elemento desiderato, seleziona l'elemento dal Ispettore scheda di Strumento per sviluppatori Firefox e fai clic con il pulsante destro del mouse (RMB) su di esso. Quindi, seleziona copia > XPath come indicato nello screenshot qui sotto.
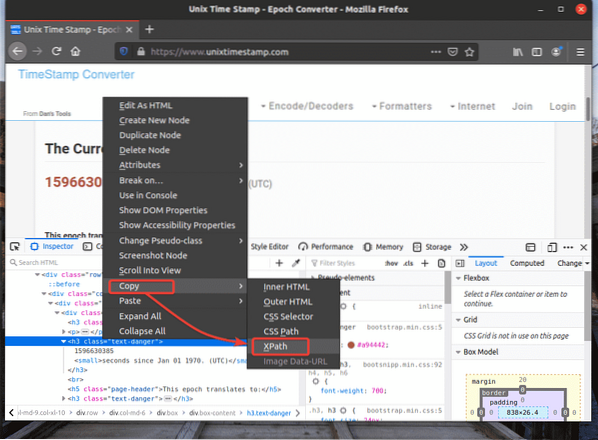
Il selettore XPath dell'elemento desiderato dovrebbe essere simile a questo.

Estrazione di dati da pagine Web utilizzando XPath Selector:
In questa sezione, ti mostrerò come selezionare gli elementi della pagina Web ed estrarre i dati da essi utilizzando i selettori XPath con la libreria Selenium Python.
Per prima cosa, crea un nuovo script Python ex01.pi e digita le seguenti righe di codici.
dal webdriver di importazione del seleniodal selenio.webdriver.Comune.chiavi di importazione chiavi
dal selenio.webdriver.Comune.per importazione da
opzioni = driver web.Opzioni Chrome()
opzioni.senza testa = Vero
browser = driver web.Chrome(executable_path="./driver/chromedriver",
opzioni=opzioni)
browser.get("https://www.unixtimestamp.com/")
timestamp = browser.find_element_by_xpath('/html/body/div[1]/div[1]
/div[2]/div[1]/div/div/h3[2]')
print('Timestamp attuale: %s' % (timestamp.testo.dividere(")[0]))
browser.vicino()
Una volta che hai finito, salva il ex01.pi Script Python.
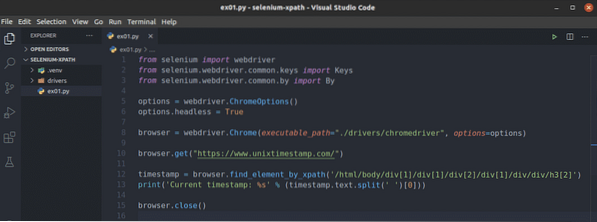
La riga 1-3 importa tutti i componenti di selenio richiesti.

La riga 5 crea un oggetto Opzioni di Chrome e la riga 6 abilita la modalità headless per il browser web Chrome.

La riga 8 crea un Chrome browser oggetto usando il chromedriver binario da autisti/ directory del progetto.

La riga 10 indica al browser di caricare il sito Web unixtimestamp.come.

La riga 12 trova l'elemento che ha i dati del timestamp dalla pagina utilizzando il selettore XPath e lo memorizza nel marca temporale variabile.
La riga 13 analizza i dati del timestamp dall'elemento e li stampa sulla console.

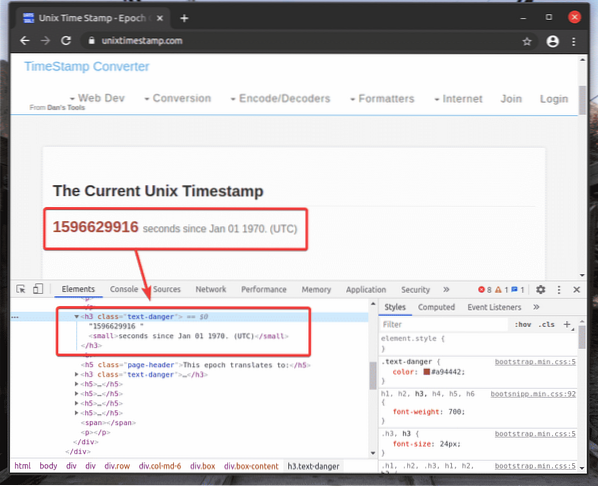
Ho copiato il selettore XPath del marcato h2 elemento da unixtimestamp.come utilizzando lo strumento per sviluppatori di Chrome.
La riga 14 chiude il browser.

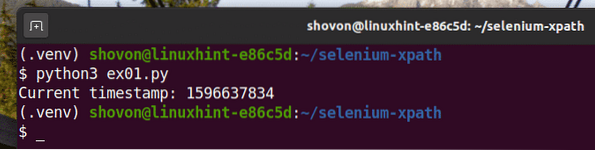
Esegui lo script Python ex01.pi come segue:
$ python3 ex01.pi
Come puoi vedere, i dati del timestamp sono stampati sullo schermo.
Ecco, ho usato il browser.find_element_by_xpath(selettore) metodo. L'unico parametro di questo metodo è il selettore, che è il selettore XPath dell'elemento.
Invece di browser.trova_elemento_per_xpath() metodo, puoi anche usare browser.find_element(Da, selettore) metodo. Questo metodo richiede due parametri. Il primo parametro Di sarà Di.XPATH poiché utilizzeremo il selettore XPath e il secondo parametro selettore sarà il selettore XPath stesso. Il risultato sarà lo stesso.
Per vedere come browser.trova_elemento() il metodo funziona per il selettore XPath, crea un nuovo script Python ex02.pi, copia e incolla tutte le righe da ex01.pi per ex02.pi e cambia linea 12 come indicato nello screenshot qui sotto.
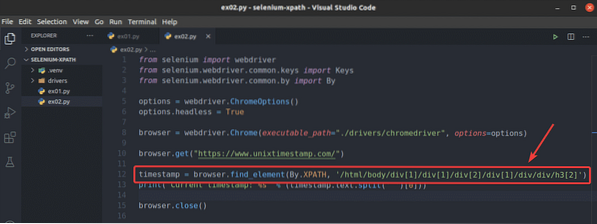
Come puoi vedere, lo script Python ex02.pi dà lo stesso risultato di ex01.pi.
$ python3 ex02.pi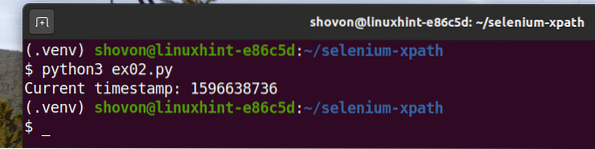
Il browser.trova_elemento_per_xpath() e browser.trova_elemento() i metodi sono usati per trovare e selezionare un singolo elemento dalle pagine web. Se vuoi trovare e selezionare più elementi usando i selettori XPath, allora devi usare browser.find_elements_by_xpath() o browser.trova_elementi() metodi.
Il browser.find_elements_by_xpath() il metodo accetta lo stesso argomento di browser.trova_elemento_per_xpath() metodo.
Il browser.trova_elementi() il metodo accetta gli stessi argomenti di browser.trova_elemento() metodo.
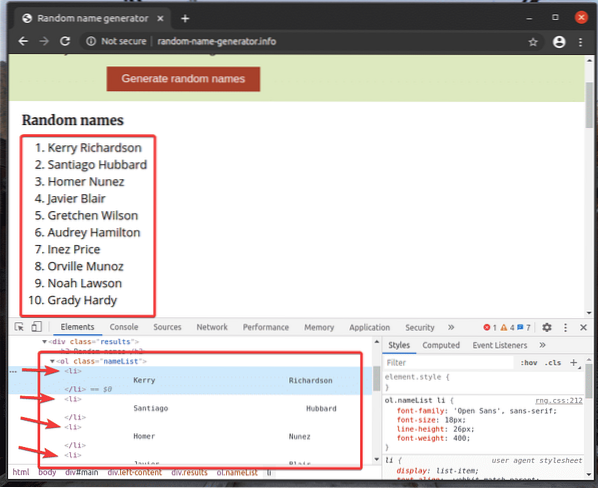
Vediamo un esempio di estrazione di un elenco di nomi utilizzando il selettore XPath da generatore di nomi casuali.Informazioni con la libreria Selenium Python.
L'elenco non ordinato (vecchio tag) ha un 10 li tag all'interno di ciascuno contenente un nome casuale. L'XPath per selezionare tutti i li tag all'interno del vecchio tag in questo caso è //*[@id=”main”]/div[3]/div[2]/ol//li
Esaminiamo un esempio di selezione di più elementi dalla pagina Web utilizzando i selettori XPath.
Crea un nuovo script Python ex03.pi e digita le seguenti righe di codici al suo interno.
dal webdriver di importazione del seleniodal selenio.webdriver.Comune.chiavi di importazione chiavi
dal selenio.webdriver.Comune.per importazione da
opzioni = driver web.Opzioni Chrome()
opzioni.senza testa = Vero
browser = driver web.Chrome(executable_path="./driver/chromedriver",
opzioni=opzioni)
browser.get("http://generatore-nome-casuale.Informazioni/")
nomi = browser.find_elements_by_xpath('
//*[@id="main"]/div[3]/div[2]/ol//li')
per nome nei nomi:
print(nome.testo)
browser.vicino()
Una volta che hai finito, salva il ex03.pi Script Python.
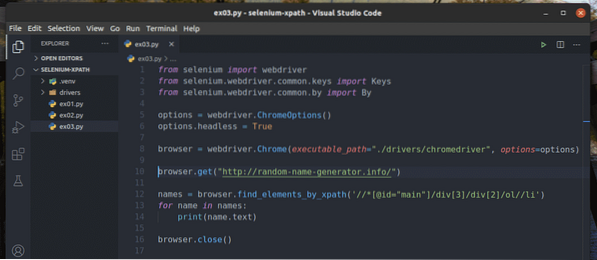
La riga 1-8 è la stessa di in ex01.pi Script Python. Quindi, non li spiegherò di nuovo qui.
La riga 10 indica al browser di caricare il generatore di nomi casuali del sito Web.Informazioni.

La riga 12 seleziona l'elenco dei nomi utilizzando il browser.find_elements_by_xpath() metodo. Questo metodo utilizza il selettore XPath //*[@id=”main”]/div[3]/div[2]/ol//li per trovare l'elenco dei nomi. Quindi, l'elenco dei nomi viene memorizzato nel nomi variabile.

Nelle righe 13 e 14, a per loop viene utilizzato per scorrere il nomi elenca e stampa i nomi sulla console.
La riga 16 chiude il browser.

Esegui lo script Python ex03.pi come segue:
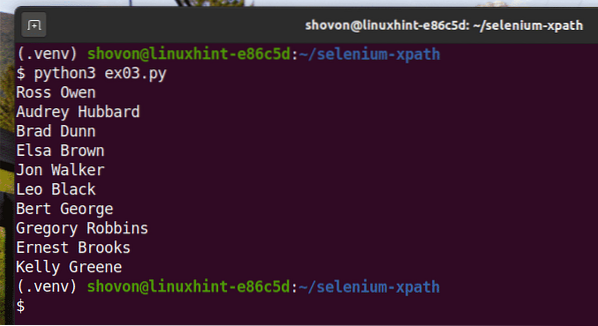
$ python3 ex03.pi
Come puoi vedere, i nomi vengono estratti dalla pagina web e stampati sulla console.
Invece di usare il browser.find_elements_by_xpath() metodo, puoi anche usare il browser.trova_elementi() metodo come prima. Il primo argomento di questo metodo è Di.XPATH, e il secondo argomento è il selettore XPath.
Per sperimentare browser.trova_elementi() metodo, crea un nuovo script Python ex04.pi, copia tutti i codici da ex03.pi per ex04.pi, e cambia la riga 12 come indicato nello screenshot qui sotto.
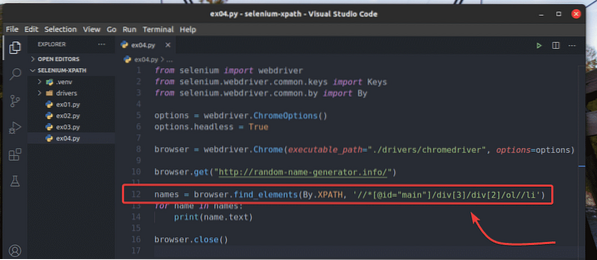
Dovresti ottenere lo stesso risultato di prima.
$ python3 ex04.pi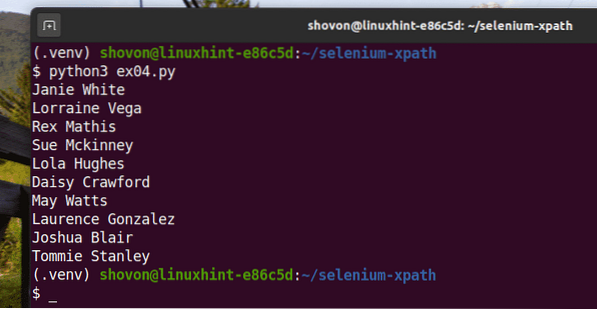
Nozioni di base su XPath Selector:
Lo strumento di sviluppo del browser Web Firefox o Google Chrome genera automaticamente il selettore XPath. Ma questi selettori XPath a volte non sono sufficienti per il tuo progetto. In tal caso, devi sapere cosa fa un certo selettore XPath per costruire il tuo selettore XPath. In questa sezione, ti mostrerò le basi dei selettori XPath. Quindi, dovresti essere in grado di creare il tuo selettore XPath.
Crea una nuova directory www/ nella directory del tuo progetto come segue:
$ mkdir -v www
Crea un nuovo file web01.html nel www/ directory e digita le seguenti righe in quel file.
Ciao mondo
Una volta che hai finito, salva il web01.html file.
Esegui un semplice server HTTP sulla porta 8080 usando il seguente comando:
$ python3 -m http.server --directory www/8080
Il server HTTP dovrebbe avviarsi.
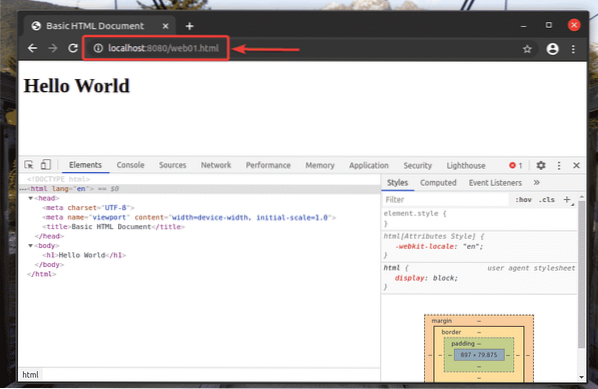
Dovresti essere in grado di accedere a web01.html file utilizzando l'URL http://localhost:8080/web01.html, come puoi vedere nello screenshot qui sotto.
Mentre lo strumento per sviluppatori Firefox o Chrome è aperto, premere
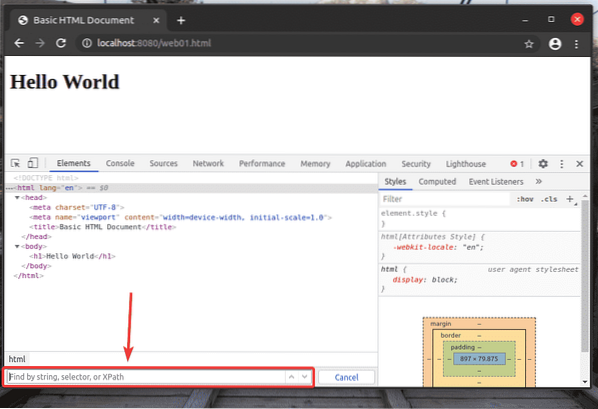
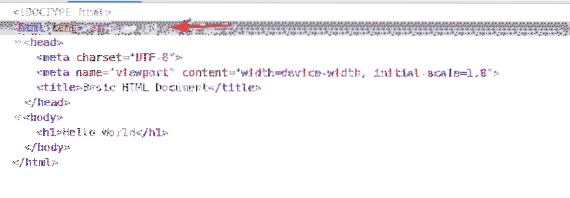
Un selettore XPath inizia con a barra (/) La maggior parte delle volte. È come un albero di directory di Linux. Il / è la radice di tutti gli elementi nella pagina web.
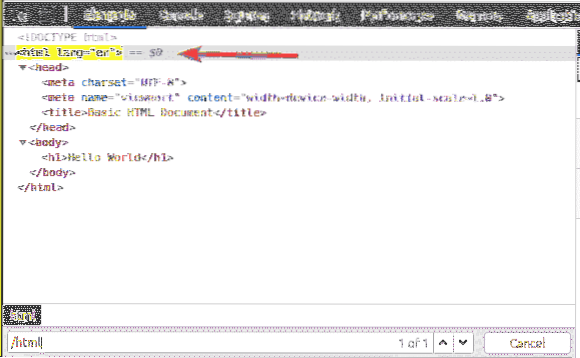
Il primo elemento è il html. Quindi, il selettore XPath /html seleziona l'intero html etichetta.
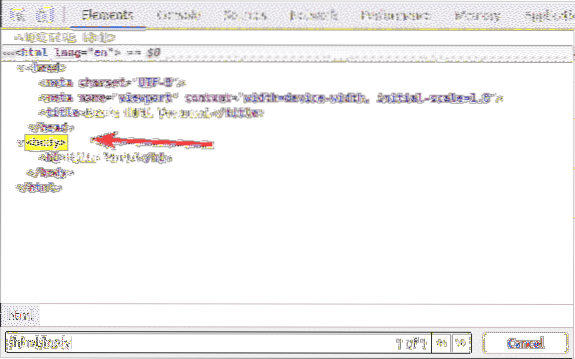
Dentro il html tag, abbiamo un corpo etichetta. Il corpo il tag può essere selezionato con il selettore XPath /html/corpo
Il h1 l'intestazione è all'interno di corpo etichetta. Il h1 l'intestazione può essere selezionata con il selettore XPath /html/corpo/h1
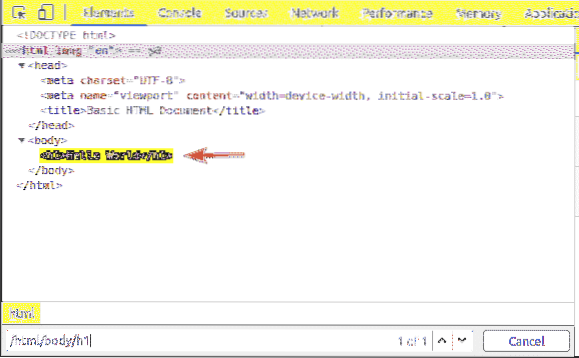
Questo tipo di selettore XPath è chiamato selettore di percorso assoluto. Nel selettore di percorso assoluto, devi attraversare la pagina web dalla radice (/) della pagina. Lo svantaggio di un selettore di percorso assoluto è che anche una leggera modifica alla struttura della pagina Web potrebbe rendere non valido il selettore XPath. La soluzione a questo problema è un selettore XPath relativo o parziale.
Per vedere come funziona il percorso relativo o il percorso parziale, crea un nuovo file web02.html nel www/ directory e digitare le seguenti righe di codici in essa.
Ciao mondo
questo è un messaggio
Ciao mondo
Una volta che hai finito, salva il web02.html file e caricalo nel tuo browser web.
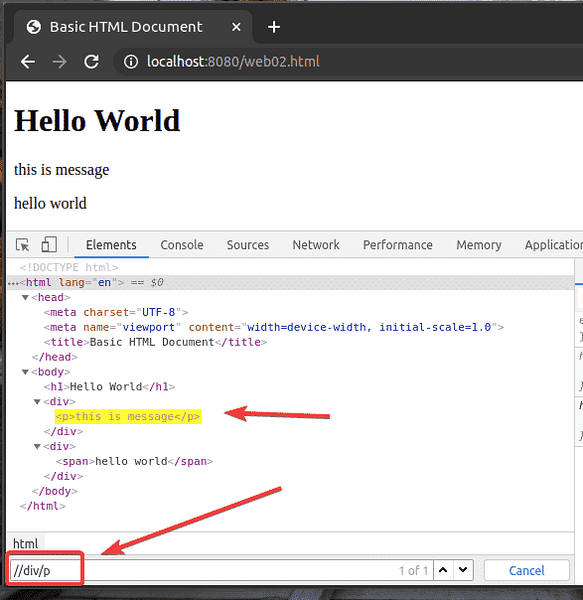
Come puoi vedere, il selettore XPath //div/p seleziona il p tag all'interno del div etichetta. Questo è un esempio di un relativo selettore XPath.
Il selettore XPath relativo inizia con //. Quindi specifichi la struttura dell'elemento che vuoi selezionare. In questo caso, div/p.
Così, //div/p significa selezionare il p elemento all'interno di a div elemento, non importa cosa viene prima di esso.
Puoi anche selezionare elementi con attributi diversi come id, classe, genere, eccetera. utilizzando il selettore XPath. Vediamo come farlo.
Crea un nuovo file web03.html nel www/ directory e digitare le seguenti righe di codici in essa.
Ciao mondo
questo è un messaggio
questo è un altro messaggio
titolo 2
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Quibusdam
eligandi doloribus sapiente, molestias quos quae non nam incidunt quis delectus
facilis magni officiis alias neque atque fuga? Unde, aut natus?
Una volta che hai finito, salva il web03.html file e caricalo nel tuo browser web.
Diciamo che vuoi selezionare tutti i div elementi che hanno il classe nome contenitore1. Per farlo, puoi usare il selettore XPath //div[@class='contenitore1']
Come puoi vedere, ho 2 elementi che corrispondono al selettore XPath //div[@class='contenitore1']
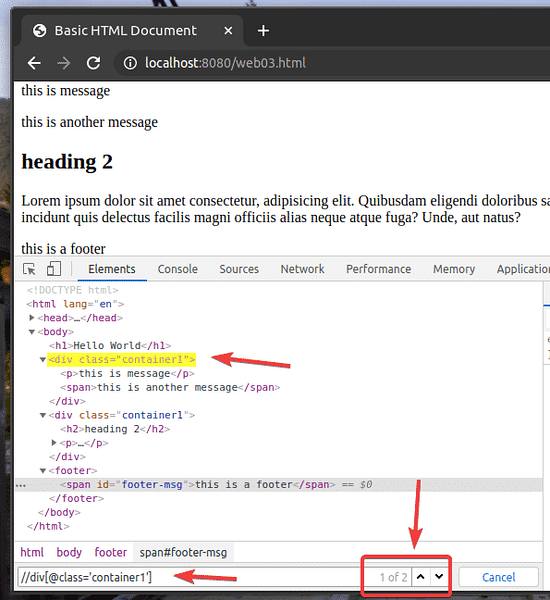
Per selezionare il primo div elemento con il classe nome contenitore1, Inserisci [1] alla fine della selezione XPath, come mostrato nello screenshot qui sotto.
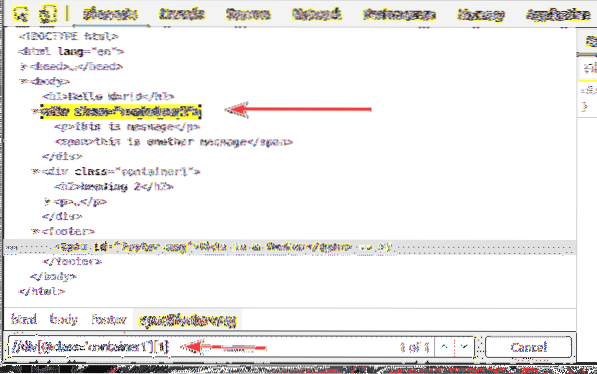
Allo stesso modo, puoi selezionare il secondo div elemento con il classe nome contenitore1 utilizzando il selettore XPath //div[@class='contenitore1'][2]
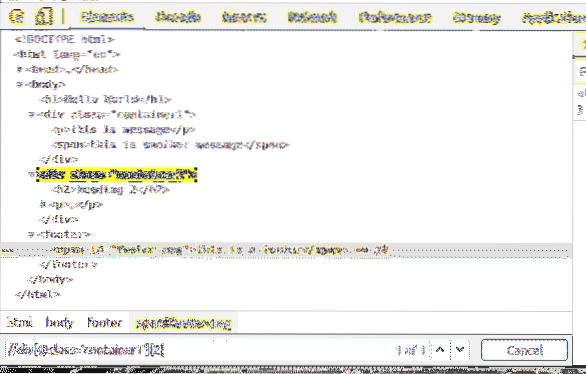
Puoi selezionare gli elementi per id anche.
Ad esempio, per selezionare l'elemento che ha il id di piè di pagina-msg, puoi usare il selettore XPath //*[@id='msg-piè di pagina']
qui, il * prima [@id='msg-piè di pagina'] è usato per selezionare qualsiasi elemento indipendentemente dal loro tag.
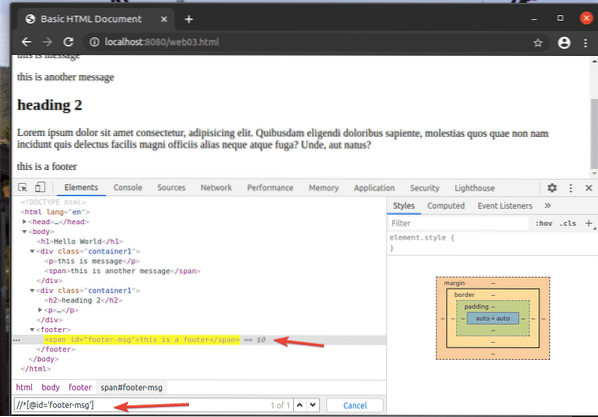
Queste sono le basi del selettore XPath. Ora dovresti essere in grado di creare il tuo selettore XPath per i tuoi progetti Selenium.
Conclusione:
In questo articolo, ti ho mostrato come trovare e selezionare elementi dalle pagine Web utilizzando il selettore XPath con la libreria Selenium Python. Ho anche discusso dei selettori XPath più comuni. Dopo aver letto questo articolo, dovresti sentirti abbastanza sicuro di selezionare elementi dalle pagine web usando il selettore XPath con la libreria Selenium Python.


