Ad esempio, se desideri ricevere aggiornamenti regolari sui tuoi prodotti preferiti per offerte di sconto o se desideri automatizzare il processo di download degli episodi della tua stagione preferita uno per uno e il sito Web non dispone di alcuna API, l'unica scelta ti rimane solo il web scraping.Lo scraping Web può essere illegale su alcuni siti Web, a seconda che un sito Web lo consenta o meno. I siti web utilizzano "robot.txt" per definire in modo esplicito gli URL che non possono essere eliminati. Puoi verificare se il sito Web lo consente o meno aggiungendo "robots.txt” con il nome di dominio del sito web. Ad esempio, https://www.Google.com/robot.TXT
In questo articolo, useremo Python per lo scraping perché è molto facile da configurare e utilizzare. Ha molte librerie integrate e di terze parti che possono essere utilizzate per raschiare e organizzare i dati. Useremo due librerie Python "urllib" per recuperare la pagina web e "BeautifulSoup" per analizzare la pagina web per applicare le operazioni di programmazione.
Come funziona il Web Scraping?
Inviamo una richiesta alla pagina web, da dove vuoi raschiare i dati. Il sito web risponderà alla richiesta con il contenuto HTML della pagina. Quindi, possiamo analizzare questa pagina Web su BeautifulSoup per un'ulteriore elaborazione. Per recuperare la pagina web, useremo la libreria "urllib" in Python.
Urllib scaricherà il contenuto della pagina web in HTML. Non possiamo applicare operazioni sulle stringhe a questa pagina web HTML per l'estrazione del contenuto e l'ulteriore elaborazione. Useremo una libreria Python "BeautifulSoup" che analizzerà il contenuto ed estrarrà i dati interessanti.
Raschiare articoli da Linuxhint.come
Ora che abbiamo un'idea di come funziona il web scraping, facciamo un po' di pratica. Cercheremo di raschiare i titoli degli articoli e i collegamenti da Linuxhint.come. Quindi apri https://linuxhint.com/ nel tuo browser.
Ora premi CRTL+U per visualizzare il codice sorgente HTML della pagina web.
Copia il codice sorgente e vai su https://htmlformatter.com/ per abbellire il codice. Dopo aver abbellito il codice, è facile ispezionarlo e trovare informazioni interessanti.
Ora, copia di nuovo il codice formattato e incollalo nel tuo editor di testo preferito come atomo, testo sublime ecc. Ora elimineremo le informazioni interessanti usando Python. Digita quanto segue
// Installa una bella libreria di zuppe, arriva urllibpreinstallato in Python
ubuntu@ubuntu:~$ sudo pip3 install bs4
ubuntu@ubuntu:~$ python3
Pitone 3.7.3 (predefinito, 7 ottobre 2019, 12:56:13)
[CGC 8.3.0] su Linux
Digita "aiuto", "copyright", "crediti" o "licenza" per ulteriori informazioni.
//Importa urllib>>> import urllib.richiesta
//Importa BeautifulSoup
>>> da bs4 import BeautifulSoup
//Inserisci l'URL che vuoi recuperare
>>> mio_url = 'https://linuxhint.com/'
//Richiedi la pagina web dell'URL usando il comando urlopen
>>> client = urllib.richiesta.urlopen(mio_url)
//Salva la pagina web HTML nella variabile “html_page”
>>> html_page = cliente.leggere()
//Chiudi la connessione URL dopo aver scaricato la pagina web
>>> cliente.vicino()
// analizza la pagina web HTML in BeautifulSoup per raschiare
>>> page_soup = BeautifulSoup(html_page, "html.analizzatore")
Ora diamo un'occhiata al codice sorgente HTML che abbiamo appena copiato e incollato per trovare cose di nostro interesse.
Puoi vedere che il primo articolo elencato su Linuxhint.com si chiama "74 Bash Operators Examples", trovalo nel codice sorgente. È racchiuso tra i tag di intestazione e il suo codice è
title="74 esempi di operatori Bash">74 operatori Bash
Esempi
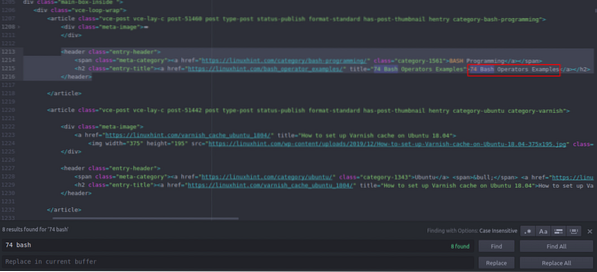
Lo stesso codice si ripete più e più volte con la modifica dei soli titoli e collegamenti degli articoli. Il prossimo articolo ha il seguente codice HTML
title="Come impostare la cache di Varnish su Ubuntu 18.04">
Come impostare la cache di Varnish su Ubuntu 18.04
Puoi vedere che tutti gli articoli compresi questi due sono racchiusi nello stesso "
” tag e usa la stessa classe “entry-title”. Possiamo usare la funzione "findAll" nella libreria Beautiful Soup per trovare ed elencare tutti i "” avendo la classe “entry-title”. Digita quanto segue nella tua console Python // Questo comando troverà tutto "” elementi tag con classe denominata
“voce-titolo”. L'output verrà memorizzato in un array.
>>> articoli = page_soup.trovaTutto("h2" ,
"classe" : "titolo-voce")
// Il numero di articoli trovati sulla prima pagina di Linuxhint.come
>>> len(articoli)
102
// Primo estratto “"elemento tag contenente il nome dell'articolo e il collegamento
>>> articoli[0]
title="74 esempi di operatori Bash">
74 Esempi di operatori Bash
// Secondo estratto “"elemento tag contenente il nome dell'articolo e il collegamento
>>> articoli[1]
title="Come impostare la cache di Varnish su Ubuntu 18.04">
Come impostare la cache di Varnish su Ubuntu 18.04
// Visualizzazione solo del testo nei tag HTML utilizzando la funzione di testo
>>> articoli[1].testo
"Come impostare la cache di Varnish su Ubuntu 18".04'
” elementi tag con classe denominata
“voce-titolo”. L'output verrà memorizzato in un array.
>>> articoli = page_soup.trovaTutto("h2" ,
"classe" : "titolo-voce")
// Il numero di articoli trovati sulla prima pagina di Linuxhint.come
>>> len(articoli)
102
// Primo estratto “"elemento tag contenente il nome dell'articolo e il collegamento
>>> articoli[0]
title="74 esempi di operatori Bash">
74 Esempi di operatori Bash
// Secondo estratto “"elemento tag contenente il nome dell'articolo e il collegamento
>>> articoli[1]
title="Come impostare la cache di Varnish su Ubuntu 18.04">
Come impostare la cache di Varnish su Ubuntu 18.04
// Visualizzazione solo del testo nei tag HTML utilizzando la funzione di testo
>>> articoli[1].testo
"Come impostare la cache di Varnish su Ubuntu 18".04'
>>> articoli[0]
title="74 esempi di operatori Bash">
74 Esempi di operatori Bash
// Secondo estratto “
"elemento tag contenente il nome dell'articolo e il collegamento
>>> articoli[1]
title="Come impostare la cache di Varnish su Ubuntu 18.04">
Come impostare la cache di Varnish su Ubuntu 18.04
// Visualizzazione solo del testo nei tag HTML utilizzando la funzione di testo
>>> articoli[1].testo
"Come impostare la cache di Varnish su Ubuntu 18".04'
title="Come impostare la cache di Varnish su Ubuntu 18.04">
Come impostare la cache di Varnish su Ubuntu 18.04
Ora che abbiamo un elenco di tutti i 102 HTML "
"Elementi tag che contengono il collegamento dell'articolo e il titolo dell'articolo. Possiamo estrarre sia i link che i titoli degli articoli. Per estrarre i collegamenti da ""tag, possiamo usare il seguente codice // Il seguente codice estrarrà il collegamento dal primo elemento tag
>>> per link negli articoli[0].find_all('a', href=True):
… print(link['href'])
…
https://linuxhint.com/bash_operator_examples/
Ora possiamo scrivere un ciclo for che itera su ogni "
" tag element nell'elenco "articles" ed estrai il link e il titolo dell'articolo. >>> per i nell'intervallo (0,10):
… print(articoli[i].testo)
… per il collegamento negli articoli[i].find_all('a', href=True):
… print(link['href']+"\n")
…
74 Esempi di operatori Bash
https://linuxhint.com/bash_operator_examples/
Come impostare la cache di Varnish su Ubuntu 18.04
https://linuxhint.com/varnish_cache_ubuntu_1804/
PineTime: uno smartwatch compatibile con Linux
https://linuxhint.com/pinetime_linux_smartwatch/
10 migliori laptop Linux economici da acquistare con un budget
https://linuxhint.com/best_cheap_linux_laptops/
Giochi rimasterizzati in HD per Linux che non hanno mai avuto una versione Linux..
https://linuxhint.com/hd_remastered_games_linux/
60 app per la registrazione dello schermo FPS per Linux
https://linuxhint.com/60_fps_screen_recording_apps_linux/
74 Esempi di operatori Bash
https://linuxhint.com/bash_operator_examples/
…tagliare…
Allo stesso modo, salvi questi risultati in un file JSON o CSV.
Conclusione
Le tue attività quotidiane non sono solo la gestione dei file o l'esecuzione dei comandi di sistema. Puoi anche automatizzare attività relative al Web come l'automazione del download di file o l'estrazione dei dati raschiando il Web in Python. Questo articolo era limitato alla semplice estrazione dei dati, ma puoi eseguire un'enorme automazione delle attività utilizzando "urllib" e "BeautifulSoup".
>>> per link negli articoli[0].find_all('a', href=True):
… print(link['href'])
…
https://linuxhint.com/bash_operator_examples/
… print(articoli[i].testo)
… per il collegamento negli articoli[i].find_all('a', href=True):
… print(link['href']+"\n")
…
74 Esempi di operatori Bash
https://linuxhint.com/bash_operator_examples/
Come impostare la cache di Varnish su Ubuntu 18.04
https://linuxhint.com/varnish_cache_ubuntu_1804/
PineTime: uno smartwatch compatibile con Linux
https://linuxhint.com/pinetime_linux_smartwatch/
10 migliori laptop Linux economici da acquistare con un budget
https://linuxhint.com/best_cheap_linux_laptops/
Giochi rimasterizzati in HD per Linux che non hanno mai avuto una versione Linux..
https://linuxhint.com/hd_remastered_games_linux/
60 app per la registrazione dello schermo FPS per Linux
https://linuxhint.com/60_fps_screen_recording_apps_linux/
74 Esempi di operatori Bash
https://linuxhint.com/bash_operator_examples/
…tagliare…


