In questa lezione vedremo cos'è Apache Kafka e come funziona insieme ai suoi casi d'uso più comuni. Apache Kafka è stato originariamente sviluppato su LinkedIn nel 2010 e si è trasferito per diventare un progetto Apache di alto livello nel 2012. Ha tre componenti principali:
- Editore-Abbonato: questo componente è responsabile della gestione e della distribuzione dei dati in modo efficiente attraverso i nodi Kafka e le applicazioni consumer che scalano molto (come letteralmente).
- Connetti API: L'API Connect è la funzionalità più utile per Kafka e consente l'integrazione di Kafka con molte origini dati esterne e sink di dati.
- Flussi di Kafka: Utilizzando Kafka Streams, possiamo considerare l'elaborazione dei dati in entrata su larga scala quasi in tempo reale.
Studieremo molto di più i concetti di Kafka nelle prossime sezioni. Andiamo avanti.
Concetti di Apache Kafka
Prima di approfondire, dobbiamo approfondire alcuni concetti in Apache Kafka. Ecco i termini che dovremmo conoscere, molto brevemente:
-
- Produttore: Questa è un'applicazione che invia un messaggio a Kafka
- Consumatore: Questa è un'applicazione che consuma dati da Kafka
- Messaggio: Dati che vengono inviati dall'applicazione del produttore all'applicazione del consumatore tramite Kafka
- Connessione: Kafka stabilisce la connessione TCP tra il cluster Kafka e le applicazioni
- Argomento: un argomento è una categoria a cui i dati inviati vengono taggati e consegnati alle applicazioni dei consumatori interessati
- Partizione argomentoNota: poiché un singolo argomento può ottenere molti dati in una volta sola, per mantenere Kafka scalabile orizzontalmente, ogni argomento è diviso in partizioni e ogni partizione può vivere su qualsiasi macchina nodo di un cluster. Proviamo a presentarlo:
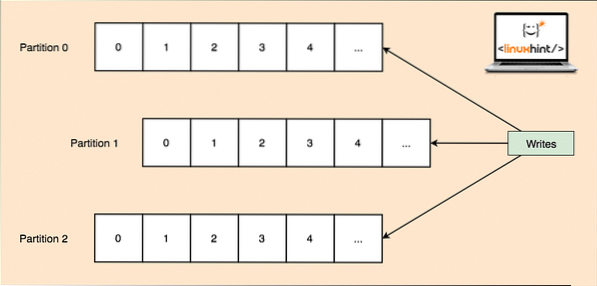
Partizioni argomento
- repliche: Come abbiamo studiato sopra che un argomento è diviso in partizioni, ogni record di messaggio viene replicato su più nodi del cluster per mantenere l'ordine e i dati di ciascun record nel caso in cui uno dei nodi muoia.
- Gruppi di consumatori: Più consumatori interessati allo stesso argomento possono essere tenuti in un gruppo denominato Gruppo di consumatori term
- Compensare: Kafka è scalabile in quanto sono i consumatori che effettivamente memorizzano quale messaggio è stato recuperato da loro per ultimo come valore di "compensazione". Ciò significa che per lo stesso argomento, l'offset del consumatore A potrebbe avere un valore di 5, il che significa che deve elaborare il sesto pacchetto successivamente e per il consumatore B, il valore dell'offset potrebbe essere 7, il che significa che deve elaborare l'ottavo pacchetto successivo. Ciò ha completamente rimosso la dipendenza dall'argomento stesso per l'archiviazione di questi metadati relativi a ciascun consumatore.
- Nodo: un nodo è un singolo server nel cluster Apache Kafka.
- Grappolo: Un cluster è un gruppo di nodi i.e., un gruppo di server.
Il concetto di Topic, Topic Partitions e offset può essere chiarito anche con una figura illustrativa:
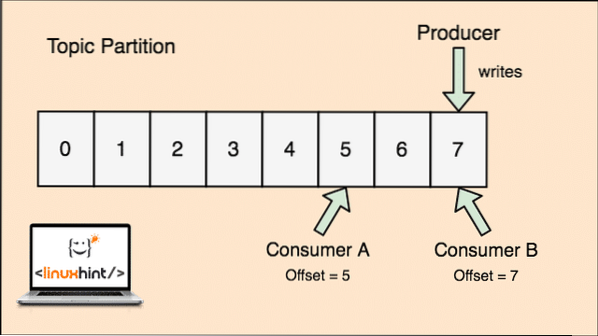
Partizione degli argomenti e offset dei consumatori in Apache Kafka
Apache Kafka come sistema di messaggistica Pubblica-sottoscrivi
Con Kafka, le applicazioni Producer pubblicano messaggi che arrivano a un Nodo Kafka e non direttamente a un Consumatore. Da questo nodo Kafka, i messaggi vengono consumati dalle applicazioni Consumer.
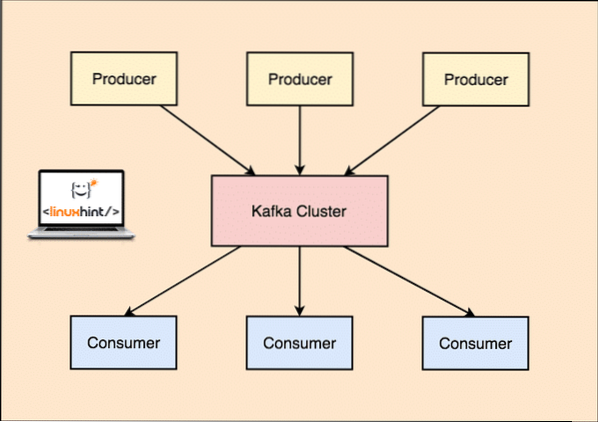
Kafka Produttore e Consumatore
Poiché un singolo argomento può ottenere molti dati in una volta sola, per mantenere Kafka scalabile orizzontalmente, ogni argomento è diviso in partizioni e ogni partizione può vivere su qualsiasi macchina nodo di un cluster.
Di nuovo, Kafka Broker non tiene traccia di quale consumatore ha consumato quanti pacchetti di dati. È il responsabilità dei consumatori di tenere traccia dei dati che ha consumato. A causa del fatto che Kafka non tiene traccia dei riconoscimenti e dei messaggi di ogni applicazione consumer, può gestire molti più consumatori con un impatto trascurabile sul throughput. In produzione, molte applicazioni seguono persino un modello di consumatori batch, il che significa che un consumatore consuma tutti i messaggi in una coda a intervalli di tempo regolari.
Installazione
Per iniziare a utilizzare Apache Kafka, deve essere installato sulla macchina. Per fare ciò, leggi Installa Apache Kafka su Ubuntu.
Caso d'uso: monitoraggio dell'utilizzo del sito web
Kafka è uno strumento eccellente da utilizzare quando abbiamo bisogno di monitorare l'attività su un sito web. I dati di monitoraggio includono e non sono limitati a visualizzazioni di pagina, ricerche, caricamenti o altre azioni che gli utenti possono intraprendere. Quando un utente si trova su un sito Web, l'utente potrebbe intraprendere un numero qualsiasi di azioni durante la navigazione nel sito Web.
Ad esempio, quando un nuovo utente si registra su un sito Web, l'attività potrebbe essere tracciata in che ordine un nuovo utente esplora le funzionalità di un sito Web, se l'utente imposta il proprio profilo secondo necessità o preferisce passare direttamente alle funzionalità del sito web. Ogni volta che l'utente fa clic su un pulsante, i metadati per quel pulsante vengono raccolti in un pacchetto di dati e inviati al cluster Kafka da cui il servizio di analisi per l'applicazione può raccogliere questi dati e produrre informazioni utili sui dati correlati. Se cerchiamo di dividere le attività in passaggi, ecco come sarà il processo:
- Un utente si registra su un sito web ed entra nella dashboard. L'utente prova ad accedere subito a una funzionalità interagendo con un pulsante.
- L'applicazione Web costruisce un messaggio con questi metadati in una partizione di argomento dell'argomento "clic".
- Il messaggio viene aggiunto al registro di commit e l'offset viene incrementato
- Il consumatore può ora estrarre il messaggio dal broker Kafka e mostrare l'utilizzo del sito Web in tempo reale e mostrare i dati passati se ripristina il suo offset su un possibile valore passato
Caso d'uso: coda di messaggi
Apache Kafka è uno strumento eccellente che può sostituire gli strumenti di broker di messaggi come RabbitMQ. La messaggistica asincrona aiuta a disaccoppiare le applicazioni e crea un sistema altamente scalabile.
Proprio come il concetto di microservizi, invece di creare un'unica grande applicazione, possiamo dividere l'applicazione in più parti e ogni parte ha una responsabilità molto specifica. In questo modo, le diverse parti possono essere scritte anche in linguaggi di programmazione completamente indipendenti! Kafka ha un sistema di partizionamento, replica e tolleranza d'errore integrato che lo rende un buon sistema di messaggistica su larga scala.
Recentemente, Kafka è anche visto come un'ottima soluzione per la raccolta dei registri in grado di gestire il broker del server di raccolta dei file di registro e fornire questi file a un sistema centrale. Con Kafka è possibile generare qualsiasi evento di cui si desidera che qualsiasi altra parte della propria applicazione venga a conoscenza.
Usare Kafka su LinkedIn
È interessante notare che Apache Kafka è stato precedentemente visto e utilizzato come un modo attraverso il quale le pipeline di dati potevano essere rese coerenti e attraverso cui i dati venivano inseriti in Hadoop. Kafka ha funzionato in modo eccellente quando erano presenti più origini dati e destinazioni e non era possibile fornire un processo di pipeline separato per ogni combinazione di origine e destinazione. L'architetto Kafka di LinkedIn, Jay Kreps, descrive bene questo problema familiare in un post sul blog:
Il mio coinvolgimento in questo è iniziato intorno al 2008 dopo aver spedito il nostro negozio di valori-chiave. Il mio prossimo progetto era provare a far funzionare una configurazione Hadoop funzionante e spostare lì alcuni dei nostri processi di raccomandazione. Avendo poca esperienza in questo settore, abbiamo naturalmente preventivato alcune settimane per ottenere dati in entrata e in uscita e il resto del nostro tempo per implementare algoritmi di previsione fantasiosi. Così iniziò un lungo sgobbone.
Apache Kafka e Flume
Se ti muovi per confrontare questi due in base alle loro funzioni, troverai molte caratteristiche comuni. Ecco qui alcuni di loro:
- Si consiglia di utilizzare Kafka quando si hanno più applicazioni che consumano i dati invece di Flume, che è fatto appositamente per essere integrato con Hadoop e può essere utilizzato solo per importare dati in HDFS e HBase. Flume è ottimizzato per le operazioni HDFS.
- Con Kafka, è uno svantaggio dover codificare i produttori e le applicazioni di consumo mentre in Flume ha molte sorgenti e sink incorporati. Ciò significa che se le esigenze esistenti corrispondono alle funzionalità di Flume, si consiglia di utilizzare Flume stesso per risparmiare tempo.
- Flume può consumare dati in volo con l'aiuto di intercettori. Può essere importante per mascherare e filtrare i dati, mentre Kafka necessita di un sistema di elaborazione del flusso esterno external.
- È possibile che Kafka utilizzi Flume come consumatore quando è necessario importare dati su HDFS e HBase. Questo significa che Kafka e Flume si integrano davvero bene.
- Kakfa e Flume possono garantire zero perdite di dati con la configurazione corretta che è anche facile da ottenere. Tuttavia, da sottolineare, Flume non replica gli eventi, il che significa che se uno dei nodi Flume si guasta, perderemo l'accesso agli eventi fino al ripristino del disco
Conclusione
In questa lezione abbiamo esaminato molti concetti su Apache Kafka. Leggi altri post basati su Kafka qui.


