Questo articolo mostra come trovare duplicati nei dati e rimuovere i duplicati utilizzando le funzioni Pandas Python.
In questo articolo, abbiamo preso un set di dati della popolazione di diversi stati negli Stati Uniti, che è disponibile in a .formato di file csv. leggeremo il .csv per mostrare il contenuto originale di questo file, come segue:
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
print(df_state)
Nella schermata seguente, puoi vedere il contenuto duplicato di questo file:
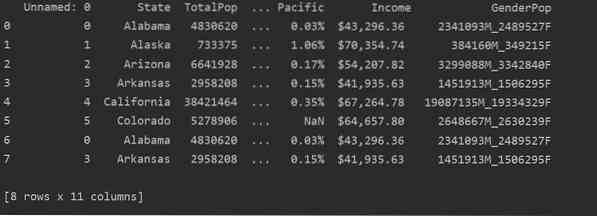
Identificazione dei duplicati in Pandas Python
È necessario determinare se i dati che stai utilizzando hanno righe duplicate. Per verificare la duplicazione dei dati, è possibile utilizzare uno dei metodi trattati nelle sezioni seguenti.
Metodo 1:
Leggi il file CSV e passalo nel frame di dati. Quindi, identifica le righe duplicate usando il duplicato() funzione. Infine, usa l'istruzione print per visualizzare le righe duplicate.
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicato()]
print("\n\nRighe duplicate: \n ".formato(Dup_Rows))
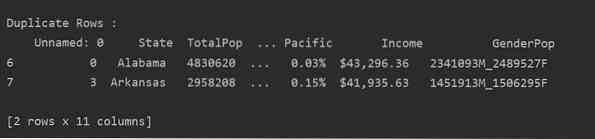
Metodo 2:
Usando questo metodo, il è_duplicato la colonna verrà aggiunta alla fine della tabella e contrassegnata come "Vero" nel caso di righe duplicate.
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
df_state["is_duplicate"]= df_state.duplicato()
print("\n ".formato(df_state))
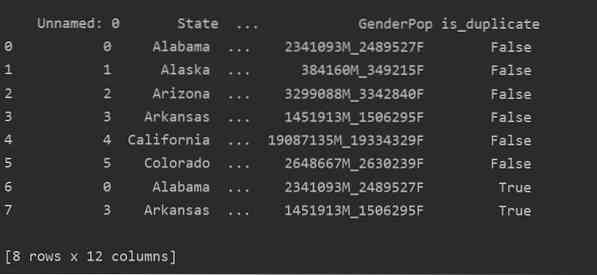
Eliminazione di duplicati in Pandas Python
Le righe duplicate possono essere rimosse dal frame di dati utilizzando la seguente sintassi:
drop_duplicates(subset=", keep=", inplace=False)
I tre parametri precedenti sono facoltativi e vengono spiegati più dettagliatamente di seguito:
mantenere: questo parametro ha tre diversi valori: Primo, Ultimo e Falso. Il valore First mantiene la prima occorrenza e rimuove i duplicati successivi, il valore Last mantiene solo l'ultima occorrenza e rimuove tutti i duplicati precedenti e il valore False rimuove tutte le righe duplicate.
sottoinsieme: etichetta utilizzata per identificare le righe duplicate
a posto: contiene due condizioni: Vero e Falso. Questo parametro rimuoverà le righe duplicate se è impostato su True.
Rimuovi i duplicati mantenendo solo la prima occorrenza
Quando usi "keep=first", verrà conservata solo l'occorrenza della prima riga e tutti gli altri duplicati verranno rimossi.
Esempio
In questo esempio, verrà conservata solo la prima riga e i restanti duplicati verranno eliminati:
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicato()]
print("\n\nRighe duplicate: \n ".formato(Dup_Righe))
DF_RM_DUP = df_state.drop_duplicates(keep='first')
print('\n\nRisultato DataFrame dopo la rimozione dei duplicati :\n', DF_RM_DUP.testa(n=5))
Nella schermata seguente, l'occorrenza della prima riga conservata viene evidenziata in rosso e le rimanenti duplicazioni vengono rimosse:
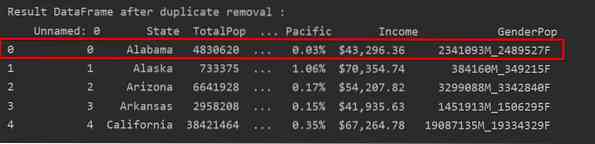
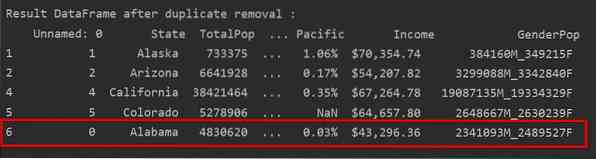
Rimuovi i duplicati mantenendo solo l'ultima occorrenza
Quando usi "keep=last", tutte le righe duplicate tranne l'ultima occorrenza verranno rimosse.
Esempio
Nell'esempio seguente, tutte le righe duplicate vengono rimosse tranne solo l'ultima occorrenza.
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicato()]
print("\n\nRighe duplicate: \n ".formato(Dup_Righe))
DF_RM_DUP = df_state.drop_duplicates(keep='ultimo')
print('\n\nRisultato DataFrame dopo la rimozione dei duplicati :\n', DF_RM_DUP.testa(n=5))
Nell'immagine seguente, i duplicati vengono rimossi e viene mantenuta solo l'ultima occorrenza di riga:
Rimuovi tutte le righe duplicate
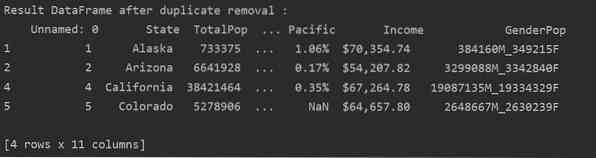
Per rimuovere tutte le righe duplicate da una tabella, imposta "keep=False", come segue:
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicato()]
print("\n\nRighe duplicate: \n ".formato(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(keep=False)
print('\n\nRisultato DataFrame dopo la rimozione dei duplicati :\n', DF_RM_DUP.testa(n=5))
Come puoi vedere nell'immagine seguente, tutti i duplicati vengono rimossi dal frame di dati:
Rimuovi i duplicati correlati da una colonna specificata
Per impostazione predefinita, la funzione controlla tutte le righe duplicate da tutte le colonne nel frame di dati specificato data. Ma puoi anche specificare il nome della colonna usando il parametro del sottoinsieme.
Esempio
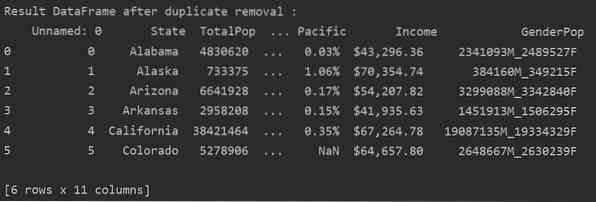
Nell'esempio seguente, tutti i duplicati correlati vengono rimossi dalla colonna "Stati".
importa panda come pddf_state=pd.read_csv("C:/Utenti/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicato()]
print("\n\nRighe duplicate: \n ".formato(Dup_Righe))
DF_RM_DUP = df_state.drop_duplicates(subset='Stato')
print('\n\nRisultato DataFrame dopo la rimozione dei duplicati :\n', DF_RM_DUP.testa(n=6))
Conclusione
Questo articolo ti ha mostrato come rimuovere le righe duplicate da un frame di dati usando il drop_duplicates() funzione in Panda Python. Puoi anche cancellare i tuoi dati di duplicazione o ridondanza usando questa funzione. L'articolo ti ha anche mostrato come identificare eventuali duplicati nel frame di dati.

