panda .read_csv
Ho già discusso parte della storia e degli usi per i panda della libreria Python. pandas è stato progettato per la necessità di un'efficiente libreria di analisi e manipolazione dei dati finanziari per Python. Per caricare i dati per l'analisi e la manipolazione, panda fornisce due metodi, Lettore dati Data e read_csv. Ho coperto il primo qui. Quest'ultimo è l'oggetto di questo tutorial.
.read_csv
Ci sono un gran numero di archivi di dati gratuiti online che includono informazioni su una varietà di campi. Ho incluso alcune di queste risorse nella sezione dei riferimenti di seguito. Poiché ho dimostrato le API integrate per estrarre in modo efficiente i dati finanziari qui, userò un'altra fonte di dati in questo tutorial.
Dati.gov offre una vasta selezione di dati gratuiti su tutto, dai cambiamenti climatici a U.S. statistiche di produzione. Ho scaricato due set di dati da utilizzare in questo tutorial. La prima è la temperatura media giornaliera massima per Bay County, Florida. Questi dati sono stati scaricati dall'U.S. Kit di strumenti per la resilienza climatica per il periodo dal 1950 ad oggi.
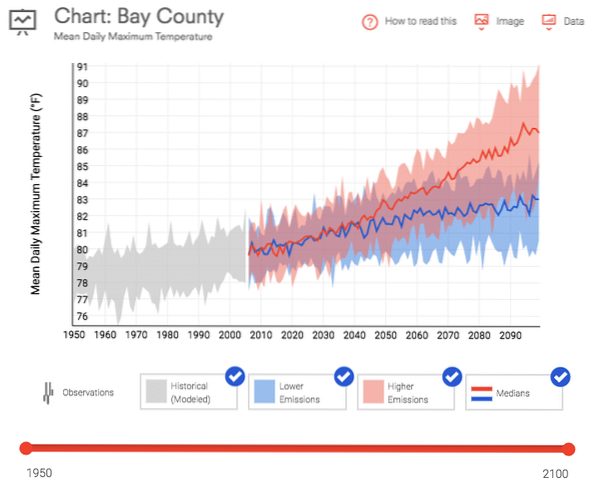
Il secondo è il Commodity Flow Survey che misura la modalità e il volume delle importazioni nel paese in un periodo di 5 anni.

Entrambi i collegamenti per questi set di dati sono forniti nella sezione dei riferimenti di seguito. Il .read_csv Il metodo, come è chiaro dal nome, caricherà queste informazioni da un file CSV e creerà un'istanza a DataFrame da quel set di dati data.
Utilizzo
Ogni volta che usi una libreria esterna, devi dire a Python che deve essere importata. Di seguito è riportata la riga di codice che importa la libreria dei panda.
importa panda come pdL'uso di base del .read_csv il metodo è sotto. Questo istanzia e popola a DataFrame df con le informazioni nel file CSV.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')Aggiungendo un paio di righe in più, possiamo ispezionare le prime e le ultime 5 righe dal DataFrame appena creato.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')print(df.testa(5))
print(df.coda(5))

Il codice ha caricato una colonna per anno, la temperatura media giornaliera in gradi Celsius (tasmax), e ha costruito uno schema di indicizzazione basato su 1 che aumenta per ogni riga di dati. È anche importante notare che le intestazioni sono popolate dal file. Con l'uso di base del metodo presentato sopra, si deduce che le intestazioni si trovano sulla prima riga del file CSV. Questo può essere modificato passando un diverso insieme di parametri al metodo.
Parametri
Ho fornito il link ai panda .read_csv documentazione nei riferimenti sottostanti. Esistono diversi parametri che possono essere utilizzati per modificare il modo in cui i dati vengono letti e formattati nel DataFrame.

Ci sono un discreto numero di parametri per il .read_csv metodo. La maggior parte non è necessaria perché la maggior parte dei set di dati che scarichi avrà un formato standard. Cioè colonne sulla prima riga e un delimitatore di virgola.
Ci sono un paio di parametri che evidenzierò nel tutorial perché possono essere utili. Un sondaggio più completo può essere preso dalla pagina della documentazione.
index_col
index_col è un parametro che può essere utilizzato per indicare la colonna che contiene l'indice. Alcuni file possono contenere un indice e altri no. Nel nostro primo set di dati, ho lasciato che Python creasse un indice. Questo è lo standard .read_csv comportamento.
Nel nostro secondo set di dati, c'è un indice incluso. Il codice qui sotto carica il DataFrame con i dati nel file CSV, ma invece di creare un indice incrementale basato su interi utilizza la colonna SHPMT_ID inclusa nel set di dati.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col = 'SHIPMT_ID')print(df.testa(5))
print(df.coda(5))
Sebbene questo set di dati utilizzi lo stesso schema per l'indice, altri set di dati potrebbero avere un indice più utile.
nrows, skiprows, usecols
Con set di dati di grandi dimensioni potresti voler caricare solo sezioni dei dati. Il nrows, saltafila, e usecols parametri ti permetteranno di suddividere i dati inclusi nel file.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col= 'SHIPMT_ID', nrows = 50)print(df.testa(5))
print(df.coda(5))
Aggiungendo il nrows parametro con un valore intero di 50, il .tail call ora restituisce linee fino a 50. Il resto dei dati nel file non viene importato.
print(df.testa(5))
print(df.coda(5))
Aggiungendo il skiprows parametro, il nostro .testa col non mostra un indice iniziale di 1001 nei dati. Poiché abbiamo saltato la riga di intestazione, i nuovi dati hanno perso l'intestazione e l'indice in base ai dati del file. In alcuni casi, potrebbe essere meglio suddividere i dati in a DataFrame piuttosto che prima di caricare i dati.

Il usecols è un parametro utile che permette di importare solo un sottoinsieme dei dati per colonna. Può essere passato un indice zero o un elenco di stringhe con i nomi delle colonne. Ho usato il codice qui sotto per importare le prime quattro colonne nel nostro nuovo DataFrame.
df = pd.read_csv('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3] )
print(df.testa(5))
print(df.coda(5))
Dal nostro nuovo .testa chiama, nostro DataFrame ora contiene solo le prime quattro colonne del set di dati.
motore
Un ultimo parametro che penso possa tornare utile in alcuni set di dati è il motore parametro. Puoi usare il motore basato su C o il codice basato su Python. Il motore C sarà naturalmente più veloce. Questo è importante se stai importando set di dati di grandi dimensioni. I vantaggi dell'analisi di Python sono un insieme più ricco di funzionalità. Questo vantaggio può significare meno se si caricano big data in memoria.
df = pd.read_csv('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID', motore = 'c' )
print(df.testa(5))
print(df.coda(5))
Azione supplementare
Ci sono molti altri parametri che possono estendere il comportamento predefinito del .read_csv metodo. Possono essere trovati nella pagina dei documenti a cui ho fatto riferimento di seguito. .read_csv è un metodo utile per caricare set di dati nei panda per l'analisi dei dati. Poiché molti dei set di dati gratuiti su Internet non dispongono di API, ciò si rivelerà molto utile per le applicazioni al di fuori dei dati finanziari in cui sono presenti API robuste per importare dati in panda.
Riferimenti
https://panda.pydata.org/panda-docs/stable/generated/panda.read_csv.html
https://www.dati.governo/
https://toolkit.clima.gov/#climate-explorer
https://www.censimento.gov/econ/cfs/pums.html

