
Quando ho iniziato a lavorare con problemi di apprendimento automatico, mi sono sentito nel panico su quale algoritmo dovrei usare should? O quale è facile da applicare? Se sei come me, questo articolo potrebbe aiutarti a conoscere l'intelligenza artificiale e gli algoritmi, i metodi o le tecniche di apprendimento automatico per risolvere eventuali problemi imprevisti o addirittura previsti.
L'apprendimento automatico è una tecnica di intelligenza artificiale così potente che può eseguire un'attività in modo efficace senza utilizzare istruzioni esplicite. Un modello ML può imparare dai suoi dati e dalla sua esperienza. Le applicazioni di machine learning sono automatiche, robuste e dinamiche. Diversi algoritmi sono sviluppati per affrontare questa natura dinamica dei problemi della vita reale. In generale, ci sono tre tipi di algoritmi di apprendimento automatico come apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo.
I migliori algoritmi di intelligenza artificiale e apprendimento automatico
La selezione della tecnica o del metodo di apprendimento automatico appropriato è uno dei compiti principali per sviluppare un progetto di intelligenza artificiale o apprendimento automatico. Perché sono disponibili diversi algoritmi e tutti hanno i loro vantaggi e la loro utilità. Di seguito stiamo narrando 20 algoritmi di apprendimento automatico sia per principianti che per professionisti. Allora, diamo un'occhiata.
1. Ingenuo Bayes
Un classificatore Naïve Bayes è un classificatore probabilistico basato sul teorema di Bayes, con l'assunzione di indipendenza tra le caratteristiche. Queste caratteristiche differiscono da un'applicazione all'altra. È uno dei comodi metodi di apprendimento automatico per i principianti da praticare.
Naïve Bayes è un modello di probabilità condizionale. Data un'istanza del problema da classificare, rappresentata da un vettore X = (Xio … Xn) rappresentando alcune n caratteristiche (variabili indipendenti), assegna all'istanza corrente le probabilità per ciascuno dei K potenziali esiti:
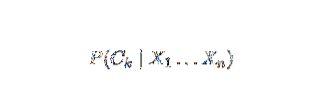 Il problema con la formulazione di cui sopra è che se il numero di caratteristiche n è significativo o se un elemento può assumere un numero elevato di valori, allora non è fattibile basare un tale modello su tabelle di probabilità. Rigeneriamo, quindi, il modello per renderlo più docile. Usando il teorema di Bayes, la probabilità condizionata può essere scritta come,
Il problema con la formulazione di cui sopra è che se il numero di caratteristiche n è significativo o se un elemento può assumere un numero elevato di valori, allora non è fattibile basare un tale modello su tabelle di probabilità. Rigeneriamo, quindi, il modello per renderlo più docile. Usando il teorema di Bayes, la probabilità condizionata può essere scritta come,
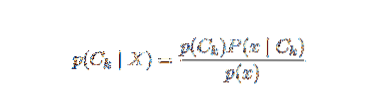
Utilizzando la terminologia della probabilità bayesiana, l'equazione di cui sopra può essere scritta come:
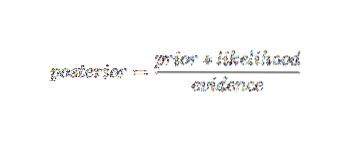
Questo algoritmo di intelligenza artificiale viene utilizzato nella classificazione del testo, i.e., analisi del sentiment, categorizzazione dei documenti, filtro antispam e classificazione delle notizie. Questa tecnica di apprendimento automatico funziona bene se i dati di input sono classificati in gruppi predefiniti. Inoltre, richiede meno dati rispetto alla regressione logistica. Supera in vari domini.
2. Supporta la macchina vettoriale
Support Vector Machine (SVM) è uno degli algoritmi di apprendimento automatico supervisionato più ampiamente utilizzati nel campo della classificazione del testo. Questo metodo viene utilizzato anche per la regressione. Può anche essere indicato come Support Vector Networks. Cortes & Vapnik hanno sviluppato questo metodo per la classificazione binaria. Il modello di apprendimento supervisionato è l'approccio di apprendimento automatico che deduce l'output dai dati di addestramento etichettati.
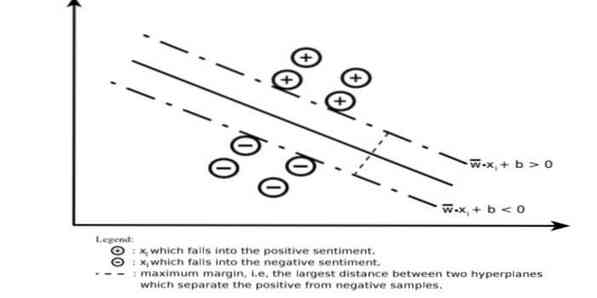
Una macchina vettore di supporto costruisce un iperpiano o un insieme di iperpiani in un'area molto alta o di dimensioni infinite. Calcola la superficie di separazione lineare con un margine massimo per un determinato training set training.
Solo un sottoinsieme dei vettori di input influenzerà la scelta del margine (cerchiato in figura); tali vettori sono chiamati vettori di supporto. Quando non esiste una superficie di separazione lineare, ad esempio, in presenza di dati rumorosi, sono appropriati algoritmi SVM con una variabile slack. Questo classificatore tenta di partizionare lo spazio dati con l'uso di delineazioni lineari o non lineari tra le diverse classi.
SVM è stato ampiamente utilizzato nei problemi di classificazione dei modelli e nella regressione non lineare. Inoltre, è una delle migliori tecniche per eseguire la categorizzazione automatica del testo. La cosa migliore di questo algoritmo è che non fa ipotesi forti sui dati.
Per implementare Support Vector Machine: librerie di data science in Python- SciKit Learn, PyML, SVMstruttura Python, LIBSVM e librerie di data science in R-Klar, e1071.
3. Regressione lineare
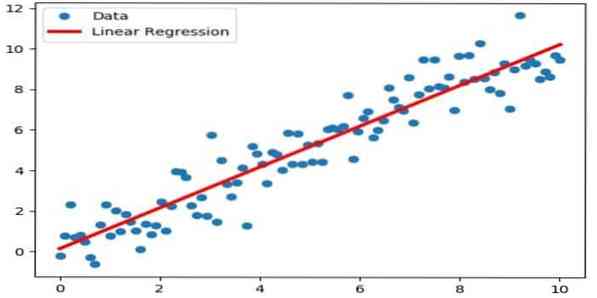
La regressione lineare è un approccio diretto utilizzato per modellare la relazione tra una variabile dipendente e una o più variabili indipendenti. Se c'è una variabile indipendente, allora si chiama regressione lineare semplice. Se è disponibile più di una variabile indipendente, si parla di regressione lineare multipla.
Questa formula viene utilizzata per stimare valori reali come il prezzo delle case, il numero di chiamate, le vendite totali in base a variabili continue. Qui, la relazione tra variabili indipendenti e dipendenti viene stabilita adattando la linea migliore. Questa linea di miglior adattamento è nota come linea di regressione ed è rappresentata da un'equazione lineare
Y= a *X + b.
Qui,
- Y - variabile dipendente
- un pendio
- X - variabile indipendente
- b - intercetta
Questo metodo di apprendimento automatico è facile da usare. Si esegue velocemente. Questo può essere utilizzato negli affari per le previsioni di vendita. Può essere utilizzato anche nella valutazione del rischio.
4. Regressione logistica
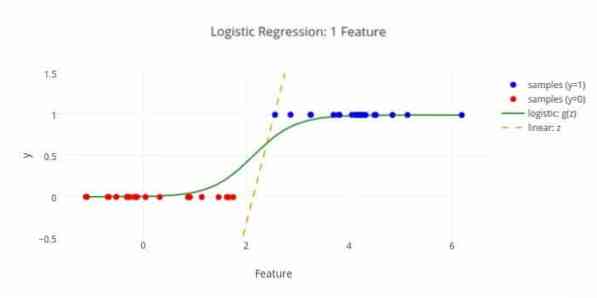
Ecco un altro algoritmo di apprendimento automatico: regressione logistica o regressione logit che viene utilizzata per stimare valori discreti (valori binari come 0/1, sì/no, vero/falso) in base a un determinato insieme della variabile indipendente. Il compito di questo algoritmo è prevedere la probabilità di un incidente adattando i dati a una funzione logit. I suoi valori di uscita sono compresi tra 0 e 1.
La formula può essere utilizzata in varie aree come l'apprendimento automatico, la disciplina scientifica e i campi medici. Può essere utilizzato per prevedere il pericolo di insorgenza di una determinata malattia in base alle caratteristiche osservate del paziente. La regressione logistica può essere utilizzata per prevedere il desiderio di un cliente di acquistare un prodotto. Questa tecnica di apprendimento automatico viene utilizzata nelle previsioni del tempo per prevedere la probabilità di pioggia.
La regressione logistica può essere suddivisa in tre tipi -
- Regressione logistica binaria
- Regressione logistica multinominale
- Regressione logistica ordinale
La regressione logistica è meno complicata. Inoltre è robusto. Può gestire effetti non lineari. Tuttavia, se i dati di addestramento sono sparsi e di grandi dimensioni, questo algoritmo ML potrebbe sovradimensionarsi. Non può prevedere risultati continui.
5. K-Vicino più vicino (KNN)
K-nearest-neighbor (kNN) è un approccio statistico ben noto per la classificazione ed è stato ampiamente studiato nel corso degli anni e si è applicato presto ai compiti di categorizzazione. Agisce come metodologia non parametrica per problemi di classificazione e regressione.
Questo metodo AI e ML è abbastanza semplice. Determina la categoria di un documento di prova t in base alla votazione di un insieme di k documenti che sono più vicini a t in termini di distanza, solitamente distanza euclidea. La regola decisionale essenziale dato un documento di prova t per il classificatore kNN è:
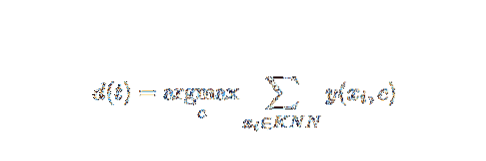
Dove y (xi,c ) è una funzione di classificazione binaria per il documento di addestramento xi (che restituisce il valore 1 se xi è etichettato con c, o 0 altrimenti), questa regola etichetta con t con la categoria che riceve il maggior numero di voti nel k -quartiere più vicino.
Possiamo essere mappati KNN alle nostre vite reali. Ad esempio, se desideri scoprire alcune persone, di cui non hai informazioni, forse preferiresti decidere riguardo ai suoi amici intimi e quindi alle cerchie in cui si muove e accedere alle sue informazioni. Questo algoritmo è computazionalmente costoso.
6. K-significa
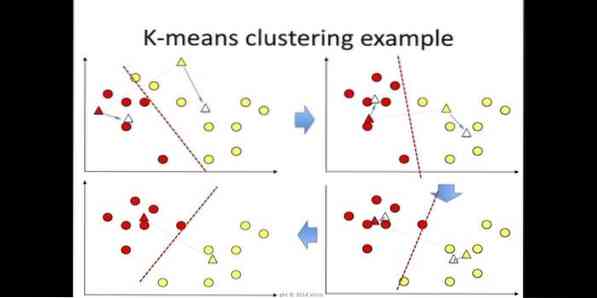
k-means clustering è un metodo di apprendimento non supervisionato accessibile per l'analisi dei cluster nel data mining. Lo scopo di questo algoritmo è dividere n osservazioni in k cluster dove ogni osservazione appartiene alla media più vicina del cluster. Questo algoritmo viene utilizzato nella segmentazione del mercato, nella visione artificiale e nell'astronomia tra molti altri domini.
7. Albero decisionale
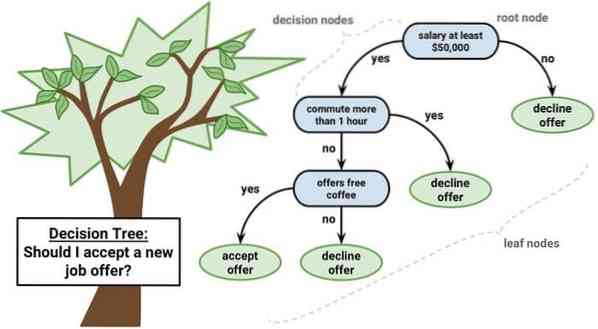
Un albero decisionale è uno strumento di supporto alle decisioni che utilizza una rappresentazione grafica, i.e., grafico ad albero o modello di decisioni. È comunemente usato nell'analisi delle decisioni e anche uno strumento popolare nell'apprendimento automatico. Gli alberi decisionali vengono utilizzati nella ricerca operativa e nella gestione delle operazioni.
Ha una struttura simile a un diagramma di flusso in cui ogni nodo interno rappresenta un 'test' su un attributo, ogni ramo rappresenta l'esito del test e ogni nodo foglia rappresenta un'etichetta di classe. Il percorso dalla radice alla foglia è noto come regole di classificazione. Consiste di tre tipi di nodi:
- Nodi decisionali: tipicamente rappresentati da quadrati,
- Nodi casuali: solitamente rappresentati da cerchi,
- Nodi finali: solitamente rappresentati da triangoli.
Un albero decisionale è semplice da capire e interpretare. Utilizza un modello a scatola bianca. Inoltre, può combinarsi con altre tecniche decisionali.
8. Foresta casuale
La foresta casuale è una tecnica popolare di apprendimento d'insieme che funziona costruendo una moltitudine di alberi decisionali al momento dell'addestramento e produce la categoria che è la modalità delle categorie (classificazione) o previsione media (regressione) di ciascun albero.
Il runtime di questo algoritmo di apprendimento automatico è veloce e può funzionare con i dati sbilanciati e mancanti. Tuttavia, quando l'abbiamo usato per la regressione, non può prevedere oltre l'intervallo nei dati di addestramento e potrebbe adattarsi eccessivamente ai dati.
9. CARRELLO
Classification and Regression Tree (CART) è un tipo di albero decisionale. Un albero decisionale funziona come un approccio di partizionamento ricorsivo e CART divide ciascuno dei nodi di input in due nodi figlio. Ad ogni livello di un albero decisionale, l'algoritmo identifica una condizione: quale variabile e livello utilizzare per suddividere il nodo di input in due nodi figli.
I passaggi dell'algoritmo CART sono riportati di seguito:
- Prendi i dati di input
- Miglior Spalato
- Migliore variabile
- Dividi i dati di input in nodi sinistro e destro
- Continua i passaggi 2-4
- Potatura dell'albero decisionale
10. Algoritmo di apprendimento automatico Apriori

L'algoritmo Apriori è un algoritmo di categorizzazione. Questa tecnica di apprendimento automatico viene utilizzata per ordinare grandi quantità di dati. Può anche essere usato per seguire come si sviluppano le relazioni e come vengono costruite le categorie. Questo algoritmo è un metodo di apprendimento non supervisionato che genera regole di associazione da un determinato set di dati.
L'algoritmo di apprendimento automatico Apriori funziona come:
- Se un insieme di elementi si verifica frequentemente, anche tutti i sottoinsiemi dell'insieme di elementi si verificano spesso.
- Se un insieme di elementi si verifica raramente, anche tutti i superinsiemi dell'insieme di elementi hanno un'occorrenza rara.
Questo algoritmo ML viene utilizzato in una varietà di applicazioni, ad esempio per rilevare reazioni avverse ai farmaci, per l'analisi del paniere di mercato e per applicazioni con completamento automatico. È semplice da implementare.
11. Analisi dei componenti principali (PCA)
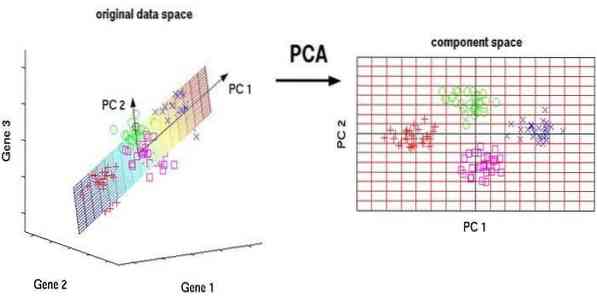
L'analisi delle componenti principali (PCA) è un algoritmo non supervisionato. Le nuove caratteristiche sono ortogonali, ciò significa che non sono correlate. Prima di eseguire la PCA, dovresti sempre normalizzare il tuo set di dati perché la trasformazione dipende dalla scala. In caso contrario, le caratteristiche che sono sulla scala più significativa domineranno i nuovi componenti principali.
La PCA è una tecnica versatile. Questo algoritmo è facile e semplice da implementare. Può essere utilizzato nell'elaborazione delle immagini.
12. CatBoost
CatBoost è un algoritmo di apprendimento automatico open source che proviene da Yandex. Il nome "CatBoost" deriva da due parole "Categoria" e "Boosting".' Può combinarsi con i framework di deep learning, i.e., TensorFlow di Google e Core ML di Apple. CatBoost può lavorare con numerosi tipi di dati per risolvere diversi problemi.
13. Dicotomizzatore iterativo 3 (ID3)
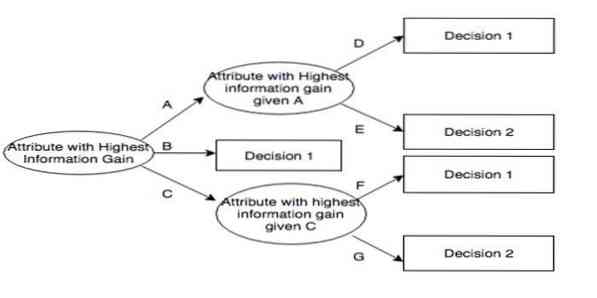
Iterative Dichotomiser 3(ID3) è una regola algoritmica di apprendimento dell'albero decisionale presentata da Ross Quinlan che viene impiegata per fornire un albero decisionale da un set di dati. È il precursore del C4.5 algoritmico ed è impiegato nei domini del processo di apprendimento automatico e comunicazione linguistica.
ID3 potrebbe adattarsi troppo ai dati di allenamento. Questa regola algoritmica è più difficile da usare su dati continui. Non garantisce una soluzione ottimale.
14. Clustering gerarchico
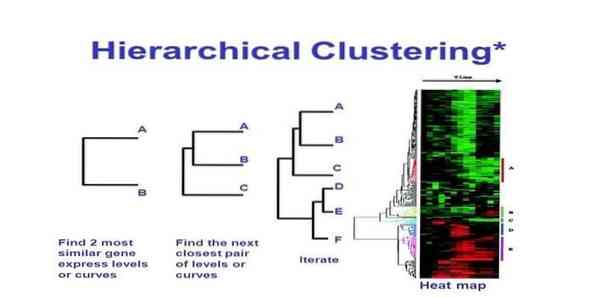
Il clustering gerarchico è un metodo di analisi dei cluster. Nel clustering gerarchico, viene sviluppato un albero di cluster (un dendrogramma) per illustrare i dati. Nel clustering gerarchico, ogni gruppo (nodo) si collega a due o più gruppi successori. Ogni nodo all'interno dell'albero del cluster contiene dati simili. Gruppo di nodi sul grafico accanto ad altri nodi simili.
Algoritmo
Questo metodo di apprendimento automatico può essere suddiviso in due modelli - dal basso verso l'alto o dall'alto al basso:
Bottom-up (raggruppamento aggregato gerarchico, HAC)
- All'inizio di questa tecnica di apprendimento automatico, prendi ogni documento come un singolo cluster.
- In un nuovo cluster, unisci due elementi alla volta. Il modo in cui le combinazioni si fondono comporta una differenza calcolata tra ogni coppia incorporata e quindi i campioni alternativi. Ci sono molte opzioni per farlo. Alcuni di loro sono:
un. Collegamento completo: Somiglianza della coppia più lontana. Una limitazione è che i valori anomali potrebbero causare la fusione di gruppi stretti più tardi di quanto sia ottimale.
b. Collegamento singolo: La somiglianza della coppia più vicina. Potrebbe causare una fusione prematura, sebbene questi gruppi siano molto diversi.
c. Media del gruppo: somiglianza tra i gruppi.
d. Somiglianza centroide: ogni iterazione unisce i cluster con il primo punto centrale simile.
- Fino a quando tutti gli elementi non si uniscono in un unico cluster, il processo di abbinamento continua.
Dall'alto verso il basso (clusterizzazione divisiva)
- I dati iniziano con un cluster combinato.
- Il cluster si divide in due parti distinte, secondo un certo grado di somiglianza.
- I cluster si dividono in due ancora e ancora fino a quando i cluster contengono solo un singolo punto dati.
15. Back-Propagation
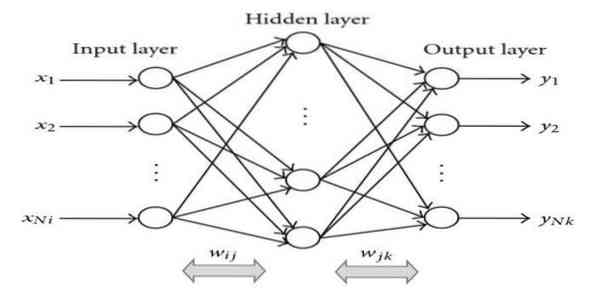
La retropropagazione è un algoritmo di apprendimento supervisionato. Questo algoritmo ML proviene dall'area delle ANN (Artificial Neural Networks). Questa rete è una rete feed-forward multistrato. Questa tecnica mira a progettare una data funzione modificando i pesi interni dei segnali di ingresso per produrre il segnale di uscita desiderato. Può essere utilizzato per la classificazione e la regressione.

L'algoritmo di retropropagazione ha alcuni vantaggi, i.e., è facile da implementare. La formula matematica utilizzata nell'algoritmo può essere applicata a qualsiasi rete. Il tempo di calcolo può essere ridotto se i pesi sono piccoli.
L'algoritmo di retropropagazione presenta alcuni inconvenienti, ad esempio potrebbe essere sensibile a dati rumorosi e valori anomali. È un approccio interamente basato su matrici. Le prestazioni effettive di questo algoritmo dipendono interamente dai dati di input. L'output può non essere numerico.
16. AdaBoost
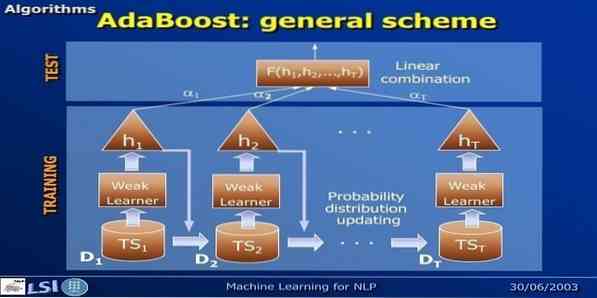
AdaBoost significa Adaptive Boosting, un metodo di apprendimento automatico rappresentato da Yoav Freund e Robert Schapire. È un meta-algoritmo e può essere integrato con altri algoritmi di apprendimento per migliorarne le prestazioni. Questo algoritmo è veloce e facile da usare. Funziona bene con grandi set di dati.
17. Apprendimento approfondito
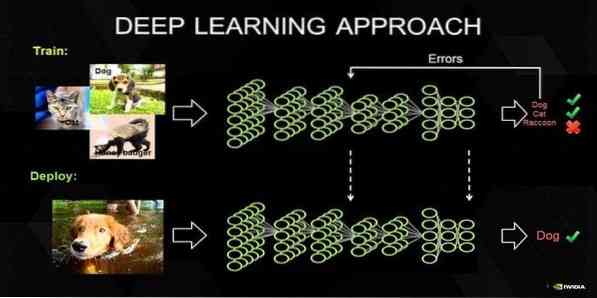
Il deep learning è un insieme di tecniche ispirate al meccanismo del cervello umano. I due principali deep learning, i.e., Le reti neurali a convoluzione (CNN) e le reti neurali ricorrenti (RNN) sono utilizzate nella classificazione del testo. Vengono utilizzati anche algoritmi di deep learning come Word2Vec o GloVe per ottenere rappresentazioni vettoriali di parole di alto livello e migliorare l'accuratezza dei classificatori addestrati con i tradizionali algoritmi di apprendimento automatico.
Questo metodo di apprendimento automatico richiede molti campioni di addestramento invece dei tradizionali algoritmi di apprendimento automatico, i.e., un minimo di milioni di esempi etichettati. D'altro canto, le tradizionali tecniche di apprendimento automatico raggiungono una soglia precisa laddove l'aggiunta di più campioni di addestramento non migliora la loro accuratezza complessiva. I classificatori di deep learning ottengono risultati migliori con più dati.
18. Algoritmo di potenziamento del gradiente

Il potenziamento del gradiente è un metodo di apprendimento automatico utilizzato per la classificazione e la regressione. È uno dei modi più potenti per sviluppare un modello predittivo. Un algoritmo di potenziamento del gradiente ha tre elementi:
- Funzione di perdita
- Allievo debole
- Modello additivo
19. Rete Hopfield
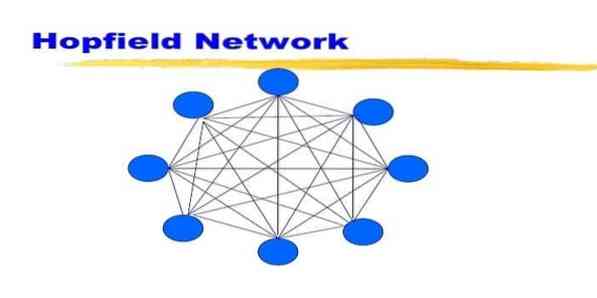
Una rete Hopfield è un tipo di rete neurale artificiale ricorrente fornita da John Hopfield nel 1982. Questa rete mira a memorizzare uno o più modelli e a richiamare i modelli completi basati su input parziali partial. In una rete Hopfield, tutti i nodi sono sia ingressi che uscite e completamente interconnessi.
20. C4.5

C4.5 è un albero decisionale inventato da Ross Quinlan. È una versione di aggiornamento di ID3. Questo programma algoritmico comprende alcuni casi base:
- Tutti i campioni della lista appartengono ad una categoria simile. Crea un nodo foglia per l'albero decisionale che dice di decidere su quella categoria.
- Crea un nodo decisionale più in alto nell'albero usando il valore atteso della classe.
- Crea un nodo decisionale più in alto nell'albero utilizzando il valore atteso.
Pensieri finali
È molto essenziale utilizzare l'algoritmo corretto basato sui dati e sul dominio per sviluppare un progetto di apprendimento automatico efficiente. Inoltre, comprendere la differenza fondamentale tra ogni algoritmo di apprendimento automatico è essenziale per affrontare "quando scelgo quale".' Come, in un approccio di apprendimento automatico, una macchina o un dispositivo ha appreso attraverso l'algoritmo di apprendimento. Credo fermamente che questo articolo ti aiuti a capire l'algoritmo. Se hai qualche suggerimento o domanda, non esitare a chiedere. Continua a leggere.


